[index] CentreCOM x900シリーズ・SwitchBlade x908 コマンドリファレンス 5.4.4
Note - この表では、おもにVCSのステータスに直接的な影響を与えるケースだけを載せています。実際は、VCSステータスには直接的な影響を与えない障害や異常もあります。これ以降の説明では、こうしたケースについても説明しています。
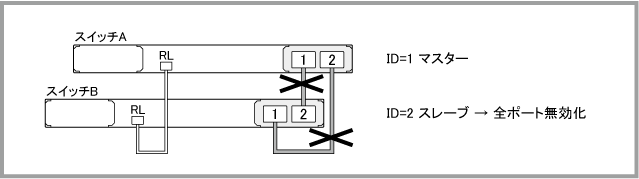
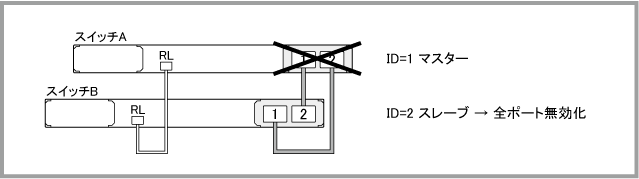
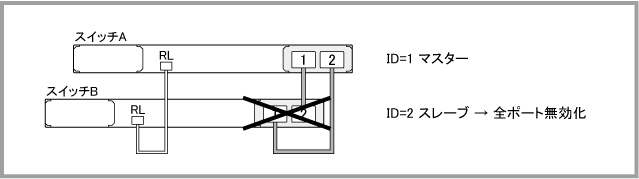
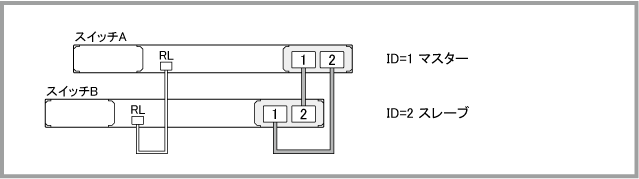
Note - 表中の「RL」は「レジリエンシーリンク用ポート」、「ST」は「STATUS」、「P1」は「PORT1」、「P2」は「PORT2」を表します。また、「緑」、「橙」はそれぞれ「緑点灯」、「橙点灯」を、「×」は「消灯」を表します。
| 正常 | ||||||||||||
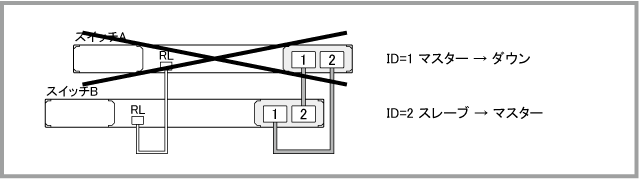
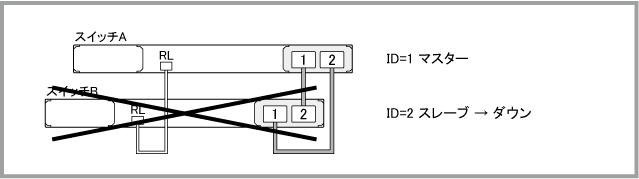
| マスター動作停止 | ||||||||||||
| スレーブ動作停止 | ||||||||||||
| スタックリンク障害(ケーブル片方AのP1) | ||||||||||||
| スタックリンク障害(ケーブル片方AのP2) | ||||||||||||
| スタックリンク障害(ケーブル両方) | ||||||||||||
| スタックリンク障害(Aのモジュール) | ||||||||||||
| スタックリンク障害(Bのモジュール) | ||||||||||||
| レジリエンシーリンク障害 | ||||||||||||
2010 Jun 10 20:11:24 local6.notice awplus-2 VCS[1049]: Link down event on stack link 2.2.1 2010 Jun 10 20:11:24 local6.err awplus-2 EXFX[1281]: Stack transport: Connection reset by peer 2010 Jun 10 20:11:24 local6.notice awplus-2 VCS[1049]: Link down event on stack link 2.2.2 2010 Jun 10 20:11:24 user.notice awplus-2 VCS[1049]: Link between members 2 and 1 is down 2010 Jun 10 20:11:24 user.crit awplus-2 VCS[1049]: Contact with the Active Master has been lost 2010 Jun 10 20:11:24 user.crit awplus-2 VCS[1049]: Member 2 (0009.41fb.cfaf) has become the Pending Master 2010 Jun 10 20:11:24 user.crit awplus-2 VCS[1049]: Stack MAC address is now 0009.41fb.cfaf 2010 Jun 10 20:11:24 user.notice awplus-2 VCS[1049]: Determining via resiliency link if previous master is still online 2010 Jun 10 20:11:25 user.crit awplus-2 VCS[1049]: Member 1 (0009.41fb.c7eb) has left stack 2010 Jun 10 20:11:25 user.crit awplus-2 NSM[1052]: Removal event on unit 1.0 has been completed 2010 Jun 10 20:11:25 user.warning awplus-2 NSM[1052]: Port down notification received for eth0 2010 Jun 10 20:11:26 user.notice awplus-2 VCS[1049]: Resiliency link has detected master is offline 2010 Jun 10 20:11:26 user.crit awplus-2 VCS[1049]: Member 2 (0009.41fb.cfaf) has become the Active Master 2010 Jun 10 20:11:26 daemon.alert awplus-2 init: Received event vcs.elected-master |
awplus# sh stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - - - - Provisioned 2 - 0009.41fb.cfaf 128 Ready Active Master Operational Status Standalone unit Stack MAC address 0009.41fb.cfaf |
Note - 同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
Note - ファームウェアバージョン5.4.3-0.2以降では、VCS使用時にバーチャルMACアドレス機能の有効化(stack virtual-mac)が必須となりました。
Note - 上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチBと同一に設定してください。
% The device needs to be restarted for this change to take effect. |
awplus(config)# platform routingratio ipv4only ↓ awplus(config)# stack management vlan 4000 ↓ awplus(config)# stack management subnet 172.21.255.64 ↓ awplus(config)# stack virtual-mac ↓ awplus(config)# stack virtual-chassis-id 127 ↓ |
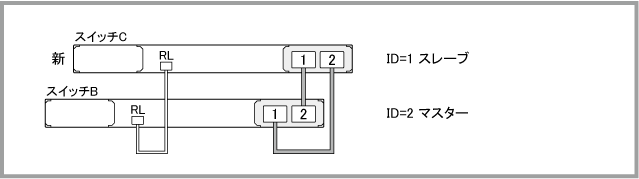
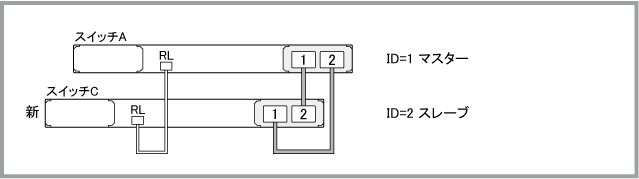
Note - スイッチCの電源は切った状態でスタックケーブルを接続してください。電源オンの状態で現在のマスターにVCS接続するとマスター重複の状態となり、プライオリティーの低い機器でリブートが発生します。
2008 Jan 21 08:30:10 daemon.crit vcg HPI: SENSOR System Board 0 - Temp: Mid Internal: Reading 86 Degrees C above maximum 85 Degrees C |
Note - 同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
Note - ファームウェアバージョン5.4.3-0.2以降では、VCS使用時にバーチャルMACアドレス機能の有効化(stack virtual-mac)が必須となりました。
Note - 上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチBと同一に設定してください。
% The device needs to be restarted for this change to take effect. |
awplus(config)# platform routingratio ipv4only ↓ awplus(config)# stack management vlan 4000 ↓ awplus(config)# stack management subnet 172.21.255.64 ↓ awplus(config)# stack virtual-mac ↓ awplus(config)# stack virtual-chassis-id 127 ↓ |
2010 Jun 10 20:15:36 local6.notice awplus VCS[1039]: Link down event on stack link 1.2.1 2010 Jun 10 20:15:37 local6.err awplus EXFX[1256]: Stack transport: Connection reset by peer 2010 Jun 10 20:15:37 local6.notice awplus VCS[1039]: Link down event on stack link 1.2.2 2010 Jun 10 20:15:37 user.notice awplus VCS[1039]: Link between members 1 and 2 is down 2010 Jun 10 20:15:37 user.crit awplus VCS[1039]: Member 2 (0009.41fb.cfaf) has left stack 2010 Jun 10 20:15:37 user.crit awplus NSM[1042]: Removal event on unit 2.0 has been completed 2010 Jun 10 20:15:38 user.warning awplus NSM[1042]: Port down notification received for eth0 |
awplus# sh stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0009.41fb.c7eb 128 Ready Active Master 2 - - - - Provisioned Operational Status Standalone unit Stack MAC address 0009.41fb.c7eb |
awplus(config)# stack 1 renumber 2 ↓ |
Note - 同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
Note - ファームウェアバージョン5.4.3-0.2以降では、VCS使用時にバーチャルMACアドレス機能の有効化(stack virtual-mac)が必須となりました。
Note - 上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチAと同一に設定してください。
% The device needs to be restarted for this change to take effect. |
awplus(config)# platform routingratio ipv4only ↓ awplus(config)# stack management vlan 4000 ↓ awplus(config)# stack management subnet 172.21.255.64 ↓ awplus(config)# stack virtual-mac ↓ awplus(config)# stack virtual-chassis-id 127 ↓ |
2008 Jan 21 08:30:10 daemon.crit vcg-2 HPI: SENSOR System Board 0 - Temp: Mid Internal: Reading 86 Degrees C above maximum 85 Degrees C |
awplus(config)# stack 1 renumber 2 ↓ |
Note - 同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
Note - ファームウェアバージョン5.4.3-0.2以降では、VCS使用時にバーチャルMACアドレス機能の有効化(stack virtual-mac)が必須となりました。
Note - 上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチAと同一に設定してください。
% The device needs to be restarted for this change to take effect. |
awplus(config)# platform routingratio ipv4only ↓ awplus(config)# stack management vlan 4000 ↓ awplus(config)# stack management subnet 172.21.255.64 ↓ awplus(config)# stack virtual-mac ↓ awplus(config)# stack virtual-chassis-id 127 ↓ |

2010 Jun 11 10:45:56 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1 2010 Jun 11 10:45:56 local6.notice awplus-2 VCS[1037]: Link down event on stack link 2.2.2 |
awplus# sh stack detail ↓ ...(中略)... Stack member 1: ------------------------------------------------------------------ ID 1 ...(中略)... Port stk1.2.1 status Down Port stk1.2.2 status Learnt neighbor 2 Stack member 2: ------------------------------------------------------------------ ID 2 ...(中略)... Port stk2.2.1 status Learnt neighbor 1 Port stk2.2.2 status Down |
2010 Jun 11 11:01:36 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1 2010 Jun 11 11:01:36 local6.notice awplus-2 VCS[1034]: Link down event on stack link 2.2.2 2010 Jun 11 11:01:37 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.2 2010 Jun 11 11:01:37 local6.notice awplus-2 VCS[1034]: Link down event on stack link 2.2.1 2010 Jun 11 11:01:37 user.notice awplus VCS[1034]: Link between members 1 and 2 is down 2010 Jun 11 11:01:37 local6.err awplus EXFX[1262]: Stack transport: Connection reset by peer 2010 Jun 11 11:01:37 user.crit awplus VCS[1034]: Member 2 (0009.41fb.cfaf) has left stack 2010 Jun 11 11:01:37 user.crit awplus NSM[1037]: Removal event on unit 2.0 has been completed |
awplus# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0009.41fb.c7eb 128 Ready Active Master 2 - - - - Provisioned Operational Status Standalone unit Stack MAC address 0009.41fb.c7eb |
vcg# show stack detail ↓ ...(中略)... Stack member 1: ------------------------------------------------------------------ ID 1 ...(中略)... Port 1.2.1 status Down Port 1.2.2 status Down |
2010 Jun 14 18:25:45 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1 2010 Jun 14 18:25:46 user.err awplus VCS[1034]: Stack member 2 has become unreachable via Layer-2 traffic 2010 Jun 14 18:25:47 user.notice awplus VCS[1034]: Link between members 1 and 2 is down 2010 Jun 14 18:25:47 user.crit awplus VCS[1034]: Member 2 (0009.41fb.cfaf) has left stack 2010 Jun 14 18:25:47 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.2 2010 Jun 14 18:25:47 local6.err awplus EXFX[1303]: Stack transport: Connection reset by peer 2010 Jun 14 18:25:47 user.crit awplus NSM[1037]: Removal event on unit 2.0 has been completed |
awplus# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0009.41fb.c7eb 128 Ready Active Master 2 - - - - Provisioned Operational Status Standalone unit Stack MAC address 0009.41fb.c7eb |
awplus# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - - - - Provisioned 2 - 0009.41fb.cfaf 128 Ready Disabled Master Operational Status Operating in failover mode Stack MAC address 0009.41fb.cfaf |
Note - SwitchBlade x908バージョン5.4.3-0.2以降では、広帯域スタックポートによるスタック接続のみがサポート対象で、スタックモジュール(AT-XEM-STK)はサポートしなくなりました。
2010 Jun 14 19:47:45 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1 2010 Jun 14 19:47:45 local6.err awplus EXFX[1303]: Stack transport: Connection reset by peer 2010 Jun 14 19:47:45 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.2 2010 Jun 14 19:47:45 user.notice awplus VCS[1034]: Link between members 1 and 2 is down 2010 Jun 14 19:47:45 user.crit awplus NSM[1037]: Removal event on unit 2.0 has been completed 2010 Jun 14 19:47:45 user.crit awplus VCS[1034]: Member 2 (0009.41fb.cfaf) has left stack |
awplus# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0009.41fb.c7eb 128 Ready Active Master 2 - - - - Provisioned Operational Status Standalone unit Stack MAC address 0009.41fb.c7eb |
Note - SwitchBlade x908バージョン5.4.3-0.2以降では、広帯域スタックポートによるスタック接続のみがサポート対象で、スタックモジュール(AT-XEM-STK)はサポートしなくなりました。
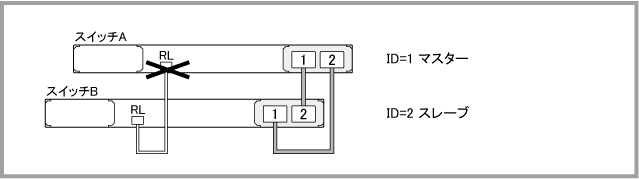
2010 Jun 14 20:04:49 user.warning awplus NSM[1037]: Port down notification received for eth0 2010 Jun 14 20:04:51 local6.err awplus-2 VCS[1039]: Resiliency link healthchecks have failed, but master is still online |
awplus# show stack detail ↓ ...(中略)... Stack member 2: ------------------------------------------------------------------ ID 2 Pending ID - MAC address 0009.41fb.cfaf Last role change Mon Jun 14 19:56:58 2010 Product type x900-24XT Role Backup Member Status Ready Priority 128 Host name awplus-2 S/W version auto synchronization On Resiliency link Failed Port stk2.2.1 status Learnt neighbor 1 Port stk2.2.2 status Learnt neighbor 1 |
Note - 同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
Note - ファームウェアバージョン5.4.3-0.2以降では、VCS使用時にバーチャルMACアドレス機能の有効化(stack virtual-mac)が必須となりました。
Note - 上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチBと同一に設定してください。
% The device needs to be restarted for this change to take effect. |
awplus(config)# platform routingratio ipv4only ↓ awplus(config)# stack management vlan 4000 ↓ awplus(config)# stack management subnet 172.21.255.64 ↓ awplus(config)# stack virtual-mac ↓ awplus(config)# stack virtual-chassis-id 127 ↓ |
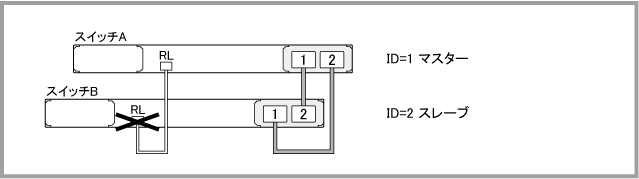
2010 Jun 14 20:29:07 local6.err awplus-2 VCS[1039]: Resiliency link healthchecks have failed, but master is still online |
Note - 同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
Note - ファームウェアバージョン5.4.3-0.2以降では、VCS使用時にバーチャルMACアドレス機能の有効化(stack virtual-mac)が必須となりました。
Note - 上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチAと同一に設定してください。% The device needs to be restarted for this change to take effect.
awplus(config)# platform routingratio ipv4only ↓ awplus(config)# stack management vlan 4000 ↓ awplus(config)# stack management subnet 172.21.255.64 ↓ awplus(config)# stack virtual-mac ↓ awplus(config)# stack virtual-chassis-id 127 ↓ |

2010 Jun 14 20:04:49 user.warning awplus NSM[1037]: Port down notification received for eth0 2010 Jun 14 20:04:51 local6.err awplus-2 VCS[1039]: Resiliency link healthchecks have failed, but master is still online |
2010 Jun 15 19:23:02 daemon.crit awplus HPI: HOTSWAP XEM 1 hotswapped out: XEM-12T 2010 Jun 15 19:23:02 local6.crit awplus EXFX[1192]: Handle event: bay 1 hsState 4 bt 274 br 0 2010 Jun 15 19:23:02 user.crit awplus NSM[1037]: Removal event on bay 1.1 has been completed |
2008 Jan 18 12:26:53 daemon.crit vcg HPI: SENSOR XEM 1 - Fan: XEM Fan 1: Reading 0 Rpm below minimum 3516 Rpm |
20:21:15 awplus HPI: HOTSWAP XEM 1 hotswapped out: XEM-12T 20:21:15 awplus EXFX[1192]: Handle event: bay 1 hsState 4 bt 274 br 0 20:21:16 awplus NSM[1037]: Removal event on bay 1.1 has been completed |
20:27:18 awplus HPI: HOTSWAP XEM 1 hotswapped in: XEM-12T 20:27:18 awplus EXFX[1192]: Handle event: bay 1 hsState 2 bt 274 br 2 20:27:20 awplus EXFX[1192]: Board XEM-12T inserted into bay 1 20:27:20 awplus EXFX[1192]: Please wait until configuration update is completed 20:27:20 awplus IMI[1039]: All users returned to config mode while switch synchronization is in progress. 20:27:20 awplus VCS[1034]: XEM-12T has been inserted into bay 1.1 20:27:21 awplus NSM[1037]: Insertion event on bay 1.1 has been completed 20:27:22 awplus IMI[1039]: Configuration update completed for port1.1.1-1.1.12 |
20:49:25 awplus-2 HPI: HOTSWAP XEM 1 hotswapped out: XEM-12T 20:49:25 awplus-2 EXFX[1196]: Handle event: bay 1 hsState 4 bt 274 br 0 20:49:25 awplus NSM[1037]: Removal event on bay 2.1 has been completed |
2008 Jan 21 02:36:11 daemon.crit vcg-2 HPI: SENSOR XEM 1 - Fan: XEM Fan 1: Reading 0 Rpm below minimum 3516 Rpm |
20:49:25 awplus-2 HPI: HOTSWAP XEM 1 hotswapped out: XEM-12T 20:49:25 awplus-2 EXFX[1196]: Handle event: bay 1 hsState 4 bt 274 br 0 20:49:25 awplus NSM[1037]: Removal event on bay 2.1 has been completed |
20:54:23 awplus-2 HPI: HOTSWAP XEM 1 hotswapped in: XEM-12T 20:54:23 awplus-2 EXFX[1196]: Handle event: bay 1 hsState 2 bt 274 br 2 20:54:25 awplus-2 EXFX[1196]: Board XEM-12T inserted into bay 1 20:54:25 awplus-2 EXFX[1196]: Please wait until configuration update is completed 20:54:26 awplus IMI[1039]: All users returned to config mode while switch synchronization is in progress. 20:54:27 awplus NSM[1037]: Insertion event on bay 2.1 has been completed 20:54:28 awplus IMI[1039]: Configuration update completed for port2.1.1-2.1.12 |
2008 Jan 21 09:42:23 daemon.crit vcg HPI: SENSOR PSU slot 2 - Device Present: BAD 2008 Jan 21 09:42:26 daemon.crit vcg HPI: HOTSWAP PSU 2 hotswapped out: AT-PWR01-AC |
2008 Jan 21 05:32:17 daemon.crit vcg HPI: SENSOR PSU slot 2 - PSU Fan Fail: BAD |
2008 Jan 21 09:42:23 daemon.crit vcg HPI: SENSOR PSU slot 2 - Device Present: BAD 2008 Jan 21 09:42:26 daemon.crit vcg HPI: HOTSWAP FOM 2 hotswapped out: AT-FAN01 |
2008 Jan 21 05:32:17 daemon.crit vcg HPI: SENSOR PSU slot 2 - PSU Fan Fail: BAD |
Note - 5.4.4-1.2は説明上使用している架空のファームウェアです。5.4.4-1.1リリース時点では実在しませんのでご注意ください。
vcg# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0009.41fb.c7eb 128 Ready Active Master 2 - 0009.41fb.cfaf 128 Ready Backup Member Operational Status Normal operation Stack MAC address 0009.41fb.c7eb |
vcg# show file systems ↓
Stack member 1:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.2M flash rw flash: static local Y
- - system rw system: virtual local -
...
Stack member 2:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.3M flash rw flash: static local Y
- - system rw system: virtual local -
...
|
vcg# dir vcg-2/flash:/*.rel ↓ ... 1401740 -rw- Jan 01 2011 00:00:00 vcg-2/flash:/SBx908-nolonger-used.rel ... vcg# delete vcg-2/flash:/SBx908-nolonger-used.rel ↓ Deleting.................................................... Successful operation |
vcg# copy tftp://10.100.10.70/SBx908-5.4.4-1.2.rel flash ↓ Enter destination file name [SBx908-5.4.4-1.2.rel]: Copying.................................................... Successful operation |
vcg# configure terminal ↓ Enter configuration commands, one per line. End with CNTL/Z. vcg(config)# boot system SBx908-5.4.4-1.2.rel ↓ VCS synchronizing file across the stack, please wait........................ File synchronization with stack member-2 successfully completed [DONE] |
vcg# show boot ↓ Boot configuration -------------------------------------------------------------------------------- Current software : SBx908-5.4.4-1.1.rel Current boot image : flash:/SBx908-5.4.4-1.2.rel Backup boot image : Not set Default boot config: flash:/default.cfg Current boot config: flash:/default.cfg (file exists) Backup boot config : Not set Autoboot status : disabled vcg# dir *.rel ↓ 14492851 -rw- May 11 2012 06:42:05 flash:/SBx908-5.4.4-1.2.rel ... vcg# dir vcg-2/flash:/*.rel ↓ 14492851 -rw- May 11 2012 06:42:05 vcg-2/flash:/SBx908-5.4.4-1.2.rel ... |
Note - 再起動中は通信断が発生します。
vcg(config)# end ↓ vcg# reload ↓ Are you sure you want to reboot the whole stack? (y/n): y ↓ ... |
Note - reload rolling/reboot rollingコマンドは、5.3.3系列またはそれ以前のファームウェアに戻すときには使用できません。
Note - reload rolling/reboot rollingコマンドは、メジャーバージョンアップには使用できません。reload rolling/reboot rollingコマンドを使用して、VCSグループの運用中にファームウェアをバージョンアップする場合は、次の手順にしたがってください。ここでは説明のため、次の環境を想定します。(以下の説明では、実際のバージョンや画面とは異なる場合があります。)
Note - 5.4.4-1.2は説明上使用している架空のファームウェアです。5.4.4-1.1リリース時点では実在しませんのでご注意ください。
vcg# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0009.41fb.c7eb 128 Ready Active Master 2 - 0009.41fb.cfaf 128 Ready Backup Member Operational Status Normal operation Stack MAC address 0009.41fb.c7eb |
vcg# show file systems ↓
Stack member 1:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.2M flash rw flash: static local Y
- - system rw system: virtual local -
...
Stack member 2:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.3M flash rw flash: static local Y
- - system rw system: virtual local -
...
|
vcg# dir vcg-2/flash:/*.rel ↓ ... 1401740 -rw- Jan 01 2011 00:00:00 vcg-2/flash:/SBx908-nolonger-used.rel ... vcg# delete vcg-2/flash:/SBx908-nolonger-used.rel ↓ Deleting.................................................... Successful operation |
vcg# copy tftp://10.100.10.70/SBx908-5.4.4-1.2.rel flash ↓ Enter destination file name [SBx908-5.4.4-1.2.rel]: Copying.................................................... Successful operation |
vcg# configure terminal ↓ Enter configuration commands, one per line. End with CNTL/Z. vcg(config)# boot system SBx908-5.4.4-1.2.rel ↓ VCS synchronizing file across the stack, please wait........................ File synchronization with stack member-2 successfully completed [DONE] |
vcg# show boot ↓ Boot configuration -------------------------------------------------------------------------------- Current software : SBx908-5.4.4-1.1.rel Current boot image : flash:/SBx908-5.4.4-1.2.rel Backup boot image : Not set Default boot config: flash:/default.cfg Current boot config: flash:/default.cfg (file exists) Backup boot config : Not set Autoboot status : disabled vcg# dir *.rel ↓ 14492851 -rw- May 11 2012 06:42:05 flash:/SBx908-5.4.4-1.2.rel ... vcg# dir vcg-2/flash:/*.rel ↓ 14492851 -rw- May 11 2012 06:42:05 vcg-2/flash:/SBx908-5.4.4-1.2.rel ... |
vcg# reboot rolling ↓ The stack master will reboot immediately and boot up with the configuration file settings. The remaining stack members will then reboot once the master has finished re-configuring. Continue the rolling reboot of the stack? (y/n): y 21:21:40 vcg VCS[1034]: Automatically rebooting stack member-1 (MAC: 0009.41fb. c7eb) due to Rolling reboot |
Note - スレーブからマスターへ遷移するとき、リンクダウンはしません。
Note - マスター(ID=1)は正常起動するまでポートをリンクアップしません。旧マスター(ID=2)も再起動中はリンクダウンするため、マスター(ID=1)がコンフィグを読み込んでから正常起動するまでの間、一時的にVCSグループの全ポートがリンクダウンしている状態になります。マスター(ID=1)の正常起動後にポートがリンクアップして通信が可能な状態になりますが、通信が復旧するまでの時間は、ネットワーク環境と使用しているプロトコルの復旧時間に依存します。
Note - 本機能はファームウェアバージョン5.4.1-2.8からサポートとなりますが、バージョンアップ時に実際に使用できるのは5.4.1-2.8よりあとのバージョンがリリースされたとき、つまり、現在のファームウェアバージョンが5.4.1-2.8以降で、新しいファームウェアバージョンが5.4.1-2.9 以降の場合となります。
Note - SDHCカードを使用する場合は、SDHCカードを装着して起動するマスターのブートローダーバージョンが1.1.6以降である必要があります。ブートローダーバージョンはshow systemコマンドの出力結果の「Bootloader version」の項目で確認できます。
vcg# show system ↓ Stack System Status Wed Mar 02 08:05:08 2011 Stack member 1: Board ID Bay Board Name Rev Serial number -------------------------------------------------------------------------------- Base 281 SwitchBlade x908 C-2 C1JB9C02U Expansion 273 Bay1 XEM-12S D-0 A1HC8207X PSU 298 PSU1 AT-PWR05-AC B-0 100525-000B1 -------------------------------------------------------------------------------- RAM: Total: 513000 kB Free: 408220 kB Flash: 63.0MB Used: 59.8MB Available: 3.2MB -------------------------------------------------------------------------------- Environment Status : Normal Uptime : 0 days 23:52:27 Bootloader version : 1.1.6 Stack member 2: Board ID Bay Board Name Rev Serial number -------------------------------------------------------------------------------- Base 281 SwitchBlade x908 D-2 C1JBA2018 Expansion 273 Bay1 XEM-12S D-0 A1HC8A02Q PSU 298 PSU1 AT-PWR05-AC B-0 100525-000BY -------------------------------------------------------------------------------- RAM: Total: 513000 kB Free: 410432 kB Flash: 63.0MB Used: 56.6MB Available: 6.4MB -------------------------------------------------------------------------------- Environment Status : Normal Uptime : 0 days 22:50:33 Bootloader version : 1.1.6 |
Note - 5.4.4-1.2は説明上使用している架空のファームウェアです。5.4.4-1.1リリース時点では実在しませんのでご注意ください。
[AlliedWare Plus] Copy_from_external_media_enabled=yes Boot_Release=SBx908-5.4.4-1.2.rel |
vcg# show file systems ↓
Stack member 1:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 35.5M flash rw flash: static local Y
- - system rw system: virtual local -
...
Stack member 2:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 38.5M flash rw flash: static local Y
- - system rw system: virtual local -
...
|
vcg# dir vcg-2/flash:/*.rel ↓ ... 1401740 -rw- Jan 01 2011 00:00:00 vcg-2/flash:/SBx908-nolonger-used.rel ... vcg# delete vcg-2/flash:/SBx908-nolonger-used.rel ↓ Deleting.................................................... Successful operation |
vcg# configure terminal ↓ Enter configuration commands, one per line. End with CNTL/Z. vcg(config)# autoboot enable ↓ |
vcg(config)# exit ↓ vcg# copy running-config before-autoboot-upgrade.cfg ↓ |
vcg# reload ↓ |
09:28:21 awplus Autoboot: autoboot.txt file detected awplus login: 09:29:21 awplus Autoboot: Restoring release from card:/SBx908-5.4.4-1.2.rel to flash:SBx908-5.4.4-1.2.rel. This may take several minutes to complete. 09:29:21 awplus Autoboot: Please wait until the device reboots. 09:30:21 awplus Autoboot: Release successfully restored 09:30:21 awplus Autoboot: Autoboot restore successful, rebooting device. |
vcg# show boot ↓ Boot configuration -------------------------------------------------------------------------------- Current software : SBx908-5.4.4-1.2.rel Current boot image : flash:/SBx908-5.4.4-1.2.rel Backup boot image : flash:/SBx908-5.4.4-1.1.rel Default boot config: flash:/default.cfg Current boot config: flash:/default.cfg (file exists) Backup boot config: Not set Autoboot status : enabled |
vcg# configure terminal ↓ Enter configuration commands, one per line. End with CNTL/Z. vcg(config)# no autoboot enable ↓ |
Note - SDHCカードを使用する場合は、SDHCカードを装着して起動するマスターのブートローダーバージョンが1.1.6以降である必要があります。ブートローダーバージョンはshow systemコマンドの出力結果の「Bootloader version」の項目で確認できます。
vcg# show system ↓ Stack System Status Wed Mar 02 08:05:08 2011 Stack member 1: Board ID Bay Board Name Rev Serial number -------------------------------------------------------------------------------- Base 281 SwitchBlade x908 C-2 C1JB9C02U Expansion 273 Bay1 XEM-12S D-0 A1HC8207X PSU 298 PSU1 AT-PWR05-AC B-0 100525-000B1 -------------------------------------------------------------------------------- RAM: Total: 513000 kB Free: 408220 kB Flash: 63.0MB Used: 59.8MB Available: 3.2MB -------------------------------------------------------------------------------- Environment Status : Normal Uptime : 0 days 23:52:27 Bootloader version : 1.1.6 Stack member 2: Board ID Bay Board Name Rev Serial number -------------------------------------------------------------------------------- Base 281 SwitchBlade x908 D-2 C1JBA2018 Expansion 273 Bay1 XEM-12S D-0 A1HC8A02Q PSU 298 PSU1 AT-PWR05-AC B-0 100525-000BY -------------------------------------------------------------------------------- RAM: Total: 513000 kB Free: 410432 kB Flash: 63.0MB Used: 56.6MB Available: 6.4MB -------------------------------------------------------------------------------- Environment Status : Normal Uptime : 0 days 22:50:33 Bootloader version : 1.1.6 |
Note - 5.4.4-1.2は説明上使用している架空のファームウェアです。5.4.4-1.1リリース時点では実在しませんのでご注意ください。
vcg# show stack ↓ Virtual Chassis Stacking summary information ID Pending ID MAC address Priority Status Role 1 - 0015.7793.23cb 128 Ready Active Master 2 - 0015.77df.f59d 128 Ready Backup Member Operational Status Normal operation Stack MAC address 0000.cd37.03db (Virtual MAC) |
vcg# configure terminal ↓ Enter configuration commands, one per line. End with CNTL/Z. vcg(config)# no boot system ↓ vcg(config)# boot system backup SBx908-5.4.4-1.1.rel ↓ VCS synchronizing file across the stack, please wait... File synchronization with stack member-2 successfully completed [DONE] |
vcg(config)# boot system card:/SBx908-5.4.4-1.2.rel ↓ VCS synchronizing file across the stack, please wait....... File synchronization with stack member-2 successfully completed [DONE] |
vcg# show boot ↓ Boot configuration -------------------------------------------------------------------------------- Current software : SBx908-5.4.4-1.1.rel Current boot image : card:/SBx908-5.4.4-1.2.rel Backup boot image : flash:/SBx908-5.4.4-1.1.rel Default boot config: flash:/default.cfg Current boot config: flash:/default.cfg (file exists) Backup boot config: Not set Autoboot status : disabled |
Note - reload rolling/reboot rollingコマンドは、メジャーバージョンアップには使用できません。
vcg# reload ↓ Are you sure you want to reboot the whole stack? (y/n): y ↓ |
(C) 2007 - 2014 アライドテレシスホールディングス株式会社
PN: 613-000751 Rev.V