バーチャルシャーシスタック(VCS) / 運用
VCS運用中の注意事項や障害発生時の対処方法について解説します。
障害発生時の対応
VCSグループの構成要素に障害が発生した場合は、障害箇所に応じた手順で対応します。
障害の発見と発生箇所の特定
障害対応の第一歩は、障害を発見し、障害箇所を特定することです。そのための方法として、LED表示の確認とCLIコマンドによる確認があります。
LED表示の確認
VCSグループ内で発生した障害を確認する第一の手段は、スイッチ本体やスタックモジュール上のLED(広帯域スタックポート使用時は本体前面のスタックLED。この場合、スタックメンバーIDはshow stackコマンドで確認してください)表示を確認することです。次に、スイッチA(ID=1)をマスター、スイッチB(ID=2)をスレーブとする構成において、さまざまなLED表示がVCSグループの状態をどう表すかについてまとめます。原則として「正常」以外のパターンでLEDが点灯しているときは、障害発生の可能性があります。
この表では、おもにVCSのステータスに直接的な影響を与えるケースだけを載せています。実際は、VCSステータスには直接的な影響を与えない障害や異常もあります。これ以降の説明では、こうしたケースについても説明しています。
表中の「RL」は「レジリエンシーリンク用ポート」、「ST」は「STATUS」、「P1」は「PORT1」、「P2」は「PORT2」を表します。また、「緑」、「橙」はそれぞれ「緑点灯」、「橙点灯」を、「×」は「消灯」を表します。
| スイッチA |
スイッチB |
判断 |
| スタック |
RL |
スタック |
RL |
| ID |
ST |
P1 |
P2 |
L/A |
D/C |
ID |
ST |
P1 |
P2 |
L/A |
D/C |
| 1 |
緑 |
緑 |
緑 |
緑 |
緑 |
2 |
橙 |
緑 |
緑 |
緑 |
緑 |
正常 |
| × |
× |
× |
× |
× |
× |
2 |
緑 |
× |
× |
× |
× |
マスター動作停止 |
| 1 |
緑 |
× |
× |
× |
× |
× |
× |
× |
× |
× |
× |
スレーブ動作停止 |
| 1 |
緑 |
× |
緑 |
緑 |
緑 |
2 |
橙 |
緑 |
× |
緑 |
緑 |
スタックリンク障害(ケーブル片方AのP1) |
| 1 |
緑 |
緑 |
× |
緑 |
緑 |
2 |
橙 |
× |
緑 |
緑 |
緑 |
スタックリンク障害(ケーブル片方AのP2) |
| 1 |
緑 |
× |
× |
緑 |
緑 |
2 |
緑 |
× |
× |
緑 |
緑 |
スタックリンク障害(ケーブル両方) |
| × |
× |
× |
× |
緑 |
緑 |
2 |
緑 |
× |
× |
緑 |
緑 |
スタックリンク障害(Aのモジュール) |
| 1 |
緑 |
× |
× |
緑 |
緑 |
× |
× |
× |
× |
緑 |
緑 |
スタックリンク障害(Bのモジュール) |
| 1 |
緑 |
緑 |
緑 |
× |
× |
2 |
橙 |
緑 |
緑 |
× |
× |
レジリエンシーリンク障害 |
CLIからの確認
LED表示でVCSグループやシステムの状況を確認して問題がありそうなときは、コンソールターミナルやTelnetクライアントからコマンドラインインターフェース(CLI)にログインして、次のコマンドを実行します。show logコマンドではVCS関連イベントのログが、show stackコマンドではスタックメンバーの各種情報を確認できます。また、show systemコマンド、show system environmentコマンドでは、各メンバーのシステム稼働状態などを確認できます。
おもな障害箇所
VCSグループの運用に直接的・間接的な影響を与える障害の発生箇所としては、大きく分けて以下のものが考えられます。
以降の各節では、これらの障害箇所ごとに、障害発生時のVCSグループの動作、障害内容の確認方法、復旧方法などを説明します。
マスター障害
マスターのスイッチ本体に発生する障害としては、おもに次の2種類が考えられます。
- マスターが動作を停止する
- マスターにステータス異常(温度上昇など)が検出される
マスターが動作を停止した場合
マスターが障害によって動作を停止した場合は、スレーブがマスターに昇格します。スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、マスターであるスイッチAがダウンすると、スイッチBがマスターに昇格して次のような構成となります。
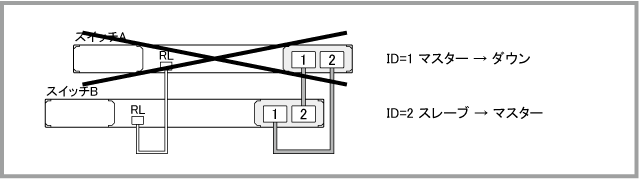
マスター切り替え後にshow logコマンドでログを確認すると、次のように表示されます。
2010 Jun 10 20:11:24 local6.notice awplus-2 VCS[1049]: Link down event on stack link 2.2.1
2010 Jun 10 20:11:24 local6.err awplus-2 EXFX[1281]: Stack transport: Connection reset by peer
2010 Jun 10 20:11:24 local6.notice awplus-2 VCS[1049]: Link down event on stack link 2.2.2
2010 Jun 10 20:11:24 user.notice awplus-2 VCS[1049]: Link between members 2 and 1 is down
2010 Jun 10 20:11:24 user.crit awplus-2 VCS[1049]: Contact with the Active Master has been lost
2010 Jun 10 20:11:24 user.crit awplus-2 VCS[1049]: Member 2 (0009.41fb.cfaf) has become the Pending Master
2010 Jun 10 20:11:24 user.crit awplus-2 VCS[1049]: Stack MAC address is now 0009.41fb.cfaf
2010 Jun 10 20:11:24 user.notice awplus-2 VCS[1049]: Determining via resiliency link if previous master is still online
2010 Jun 10 20:11:25 user.crit awplus-2 VCS[1049]: Member 1 (0009.41fb.c7eb) has left stack
2010 Jun 10 20:11:25 user.crit awplus-2 NSM[1052]: Removal event on unit 1.0 has been completed
2010 Jun 10 20:11:25 user.warning awplus-2 NSM[1052]: Port down notification received for eth0
2010 Jun 10 20:11:26 user.notice awplus-2 VCS[1049]: Resiliency link has detected master is offline
2010 Jun 10 20:11:26 user.crit awplus-2 VCS[1049]: Member 2 (0009.41fb.cfaf) has become the Active Master
2010 Jun 10 20:11:26 daemon.alert awplus-2 init: Received event vcs.elected-master
マスター切り替え後にshow stackコマンドでメンバーの情報を確認すると、次のようにスイッチB(ID=2)がマスターになっていることがわかります。スイッチA(ID=1)はすでにダウンしているため表示されません。
awplus# sh stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - - - - Provisioned
2 - 0009.41fb.cfaf 128 Ready Active Master
Operational Status Standalone unit
Stack MAC address 0009.41fb.cfaf
マスターの切り替えが完了するとネットワークはまた以前のように動作しはじめますが、このままでは利用可能な帯域が半減していますし、冗長性も失われたままとなりますので、通常の運用では、スイッチAをVCSグループから取り外し、代わりのスイッチ(以下ではスイッチCと呼びます)を再接続する必要があります。以下、そのための手順を説明します。
なお、ここではマスターが停止した原因として、マスターのスイッチ本体が故障したケースを想定しています。電源ユニットの故障によりマスターが停止した場合の対応方法については、「電源ユニット障害」をご参照ください。
- スイッチA(旧マスター)の電源を切ります。
- スイッチAのスタックモジュールからスタックケーブルを取り外します。
- スイッチAからスタックモジュールを取り外します。
- スイッチC(スイッチAの代替機)を単体起動し、ファームウェアバージョン統一などの初期設定を行います(導入編を参照)。
- スイッチCにスタックモジュールを取り付け、スタックケーブルは接続せずに起動します。
- スタックモジュール上の ID LED を見てスイッチCのID を確認します。 ID=1 であれば、スイッチAと同じなので特に何もする必要はありません。 ID=1 でない場合は、スタックモジュール上のセレクトボタンを押してスイッチC をID=1 にします。セレクトボタンを押した後は自動的に再起動するので、 起動が完了してID=1 になったことを確認します。
運用しているスタックの設定を確認して、必要に応じてスイッチCのスタックの設定を修正・保存した後、スイッチCの電源を切ります。
以下のコマンドを用いてスイッチチップに対する設定やVCSに関する設定を変更している場合は、運用中のスイッチBと同一に設定します。
同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
バーチャルMACアドレス機能は、stack enableコマンドでVCS機能を有効化すると自動的に有効化されます。stack virtual-macコマンドをno形式で実行することにより無効化もできますが、VCS使用時は必ずバーチャルMACアドレス機能を有効にした状態で運用してください。無効状態での運用はサポート対象外となります。
上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチBと同一に設定してください。
% The device needs to be restarted for this change to take effect.
以下の例では、 ルーティングテーブル用メモリー領域をすべてIPv4に割り当て、 VCS管理用VLAN 4000、 VCS管理用サブネットアドレス 172.21.255.64、バーチャルシャーシID 127(0x07f)と仮定しています。
awplus(config)# platform routingratio ipv4only ↓
awplus(config)# stack management vlan 4000 ↓
awplus(config)# stack management subnet 172.21.255.64 ↓
awplus(config)# stack virtual-mac ↓
awplus(config)# stack virtual-chassis-id 127 ↓
初期設定のままであれば、何もせずにスイッチCの電源を切ります。
- スイッチCのスタックモジュールにスタックケーブルを接続し、スイッチAに接続されていた拡張モジュールをスイッチCに装着しなおします。さらに、起動状況を確認するため、コンソールケーブルをスイッチCに接続した上で、スイッチCの電源を入れます。
スイッチCの電源は切った状態でスタックケーブルを接続してください。電源オンの状態で現在のマスターにVCS接続するとマスター重複の状態となり、プライオリティーの低い機器でリブートが発生します。
- スイッチCが起動し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、スイッチCはスレーブとしてVCSグループに加わります。
- スイッチAに接続されていたケーブル類を以前と同じ構成になるように注意しながらスイッチCに接続します。この結果、VCSグループの構成は次のようになります。
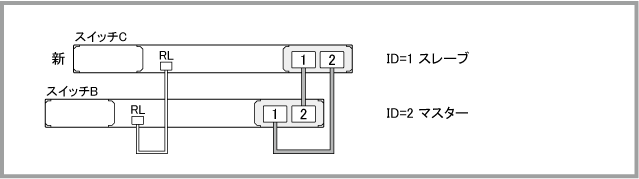
マスターにステータス異常が検出された場合
マスターのシステムに温度上昇などのステータス異常が検出された場合は、show logコマンドでログを確認すると、次のように表示されます。この例の「SENSOR System Board 0 - Temp ...」は、システム温度の異常が検出されたことを示しています。
2008 Jan 21 08:30:10 daemon.crit vcg HPI: SENSOR System Board 0 - Temp: Mid Internal: Reading 86 Degrees C above maximum 85 Degrees C
マスターのシステムステータス異常は、show systemコマンドの「Environment Status」欄が「**Fault**」になることからわかります。また、show system environmentコマンドの出力では、スイッチAの「Overall Status」欄が「**Fault**」になり、また、該当異常項目の「Status」欄が「FAULT」になり、さらにスイッチAのFAULT LEDが赤く点滅することからもわかります。
システムステータスの異常はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力からマスターのシステムステータス異常を知ることはできません。
マスターのシステムステータス異常はマスターの動作停止につながるおそれがあるため、ステータス異常を検出したら、以下の手順にしたがってマスターを交換してください。
- スイッチA(マスター)の電源を切ります。
- スイッチAのスタックモジュールからスタックケーブルを取り外します。
- スイッチAからスタックモジュールを取り外します。
- スイッチC(スイッチAの代替機)を単体起動し、ファームウェアバージョン統一などの初期設定を行います(導入編を参照)。
- スイッチCにスタックモジュールを取り付け、スタックケーブルは接続せずに起動します。
- スタックモジュール上の ID LED を見てスイッチCのID を確認します。 ID=1 であれば、スイッチAと同じなので特に何もする必要はありません。 ID=1 でない場合は、スタックモジュール上のセレクトボタンを押してスイッチC をID=1 にします。セレクトボタンを押した後は自動的に再起動するので、 起動が完了してID=1 になったことを確認します。
運用しているスタックの設定を確認して、必要に応じてスイッチCのスタックの設定を修正・保存した後、スイッチCの電源を切ります。
以下のコマンドを用いてスイッチチップに対する設定やVCSに関する設定を変更している場合は、運用中のスイッチBと同一に設定します。
同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
バーチャルMACアドレス機能は、stack enableコマンドでVCS機能を有効化すると自動的に有効化されます。stack virtual-macコマンドをno形式で実行することにより無効化もできますが、VCS使用時は必ずバーチャルMACアドレス機能を有効にした状態で運用してください。無効状態での運用はサポート対象外となります。
上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチBと同一に設定してください。
% The device needs to be restarted for this change to take effect.
以下の例では、 ルーティングテーブル用メモリー領域をすべてIPv4に割り当て、 VCS管理用VLAN 4000、 VCS管理用サブネットアドレス 172.21.255.64、バーチャルシャーシID 127(0x07f)と仮定しています。
awplus(config)# platform routingratio ipv4only ↓
awplus(config)# stack management vlan 4000 ↓
awplus(config)# stack management subnet 172.21.255.64 ↓
awplus(config)# stack virtual-mac ↓
awplus(config)# stack virtual-chassis-id 127 ↓
初期設定のままであれば、何もせずにスイッチCの電源を切ります。
- スイッチCのスタックモジュールにスタックケーブルを接続し、スイッチAに接続されていた拡張モジュールをスイッチCに装着しなおします。さらに、起動状況を確認するため、コンソールケーブルをスイッチCに接続した上で、スイッチCの電源を入れます。
- スイッチCが起動し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、スイッチCはスレーブとしてVCSグループに加わります。
- スイッチAに接続されていたケーブル類を以前と同じ構成になるように注意しながらスイッチCに接続します。
スレーブ障害
スレーブのスイッチ本体に発生する障害としては、おもに次の2種類が考えられます。
- スレーブが動作を停止する
- スレーブにステータス異常(温度上昇など)が検出される
スレーブが動作を停止した場合
スレーブが障害によって動作を停止した場合は、VCSグループの動作自体には影響がありません。スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、スレーブであるスイッチBがダウンしても、マスターのスイッチAだけでVCSグループとしての動作を継続します。
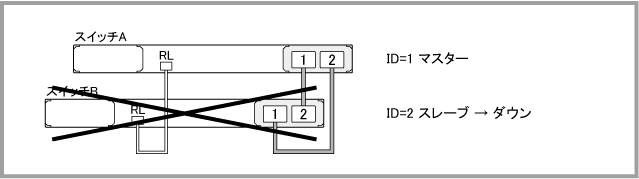
スレーブがダウンした後にshow logコマンドでログを確認すると、次のように表示されます。
2010 Jun 10 20:15:36 local6.notice awplus VCS[1039]: Link down event on stack link 1.2.1
2010 Jun 10 20:15:37 local6.err awplus EXFX[1256]: Stack transport: Connection reset by peer
2010 Jun 10 20:15:37 local6.notice awplus VCS[1039]: Link down event on stack link 1.2.2
2010 Jun 10 20:15:37 user.notice awplus VCS[1039]: Link between members 1 and 2 is down
2010 Jun 10 20:15:37 user.crit awplus VCS[1039]: Member 2 (0009.41fb.cfaf) has left stack
2010 Jun 10 20:15:37 user.crit awplus NSM[1042]: Removal event on unit 2.0 has been completed
2010 Jun 10 20:15:38 user.warning awplus NSM[1042]: Port down notification received for eth0
また、show stackコマンドでメンバーの情報を確認すると、次のようにマスターとして動作しているスイッチA(ID=1)だけが表示されます。
awplus# sh stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0009.41fb.c7eb 128 Ready Active Master
2 - - - - Provisioned
Operational Status Standalone unit
Stack MAC address 0009.41fb.c7eb
このように、スレーブがダウンしてもネットワークの運用には直接影響がありませんが、このままでは利用可能な帯域が半減していますし、冗長性も失われたままとなりますので、通常の運用では、スイッチBをVCSグループから取り外し、代わりのスイッチ(以下ではスイッチCと呼びます)を再接続する必要があります。以下、そのための手順を説明します。
なお、ここではスレーブが停止した原因として、スレーブのスイッチ本体が故障したケースを想定しています。電源ユニットの故障によりスレーブが停止した場合の対応方法については、「電源ユニット障害」をご参照ください。
- スイッチB(旧スレーブ)の電源を切ります。
- スイッチBのスタックモジュールからスタックケーブルを取り外します。
- スイッチBからスタックモジュールを取り外します。
- スイッチC(スイッチBの代替機)を単体起動し、ファームウェアバージョン統一などの初期設定を行います(導入編を参照)。
- スイッチCにスタックモジュールを取り付け、スタックケーブルは接続せずに起動します。
- スタックモジュール上のID LED を見てスイッチC のID を確認します。スイッチB(旧スレーブ)と同じID=2 であれば、特に何もする必要はありません。ID=2 でない場合は、stack renumberコマンドを実行してスイッチCをID=2にします。(以下の例はID=1 であったと仮定しています)
awplus(config)# stack 1 renumber 2 ↓
運用しているスタックの設定を確認して、必要に応じてスイッチCのスタックの設定を修正・保存した後、スイッチCの電源を切ります。
以下のコマンドを用いてスイッチチップに対する設定やVCSに関する設定を変更している場合は、運用中のスイッチA(マスター)と同一に設定します。
同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
バーチャルMACアドレス機能は、stack enableコマンドでVCS機能を有効化すると自動的に有効化されます。stack virtual-macコマンドをno形式で実行することにより無効化もできますが、VCS使用時は必ずバーチャルMACアドレス機能を有効にした状態で運用してください。無効状態での運用はサポート対象外となります。
上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチAと同一に設定してください。
% The device needs to be restarted for this change to take effect.
以下の例では、 ルーティングテーブル用メモリー領域をすべてIPv4に割り当て、 VCS管理用VLAN 4000、VCS管理用サブネットアドレス 172.21.255.64、バーチャルシャーシID 127(0x07f)と仮定しています。
awplus(config)# platform routingratio ipv4only ↓
awplus(config)# stack management vlan 4000 ↓
awplus(config)# stack management subnet 172.21.255.64 ↓
awplus(config)# stack virtual-mac ↓
awplus(config)# stack virtual-chassis-id 127 ↓
初期設定のままであれば、何もせずにスイッチCの電源を切ります。
- スイッチCのスタックモジュールにスタックケーブルを接続し、スイッチBに接続されていた拡張モジュールをスイッチCに装着しなおします。さらに、起動状況を確認するため、コンソールケーブルをスイッチCに接続した上で、スイッチCの電源を入れます。
- スイッチCが起動し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、スイッチCはスレーブとしてVCSグループに加わります。
- スイッチBに接続されていたケーブル類を以前と同じ構成になるように注意しながらスイッチCに接続します。この結果、VCSグループの構成は次のようになります。
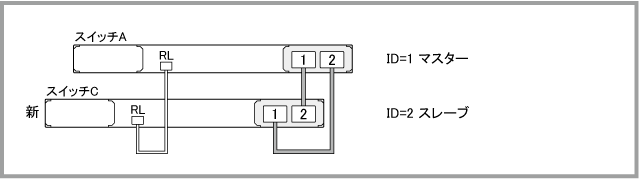
スレーブにステータス異常が検出された場合
スレーブのシステムに温度上昇などのステータス異常が検出された場合は、show logコマンドでログを確認すると、次のように表示されます。この例の「SENSOR System Board 0 - Temp ...」は、システム温度の異常が検出されたことを示しています。
2008 Jan 21 08:30:10 daemon.crit vcg-2 HPI: SENSOR System Board 0 - Temp: Mid Internal: Reading 86 Degrees C above maximum 85 Degrees C
スレーブのシステムステータス異常は、show systemコマンドの「Environment Status」欄が「**Fault**」になることからわかります。また、show system environmentコマンドの出力では、スイッチBの「Overall Status」欄が「**Fault**」になり、また、該当異常項目の「Status」欄が「FAULT」になり、さらにスイッチBのFAULT LEDが赤く点滅することからもわかります。
システムステータスの異常はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力からスレーブのシステムステータス異常を知ることはできません。
スレーブのシステムステータス異常はスレーブの動作停止につながるおそれがあるので、ステータス異常を検出したら、以下の手順にしたがってスレーブを交換してください。
- スイッチB(スレーブ)の電源を切ります。
- スイッチBのスタックモジュールからスタックケーブルを取り外します。
- スイッチBからスタックモジュールを取り外します。
- スイッチC(スイッチBの代替機)を単体起動し、ファームウェアバージョン統一などの初期設定を行います(導入編を参照)。
- スイッチCにスタックモジュールを取り付け、スタックケーブルは接続せずに起動します。
- スタックモジュール上のID LED を見てスイッチC のID を確認します。スイッチB(旧スレーブ)と同じID=2 であれば、特に何もする必要はありません。ID=2 でない場合は、stack renumberコマンドを実行してスイッチCをID=2にします。(以下の例はID=1 であったと仮定しています)
awplus(config)# stack 1 renumber 2 ↓
運用しているスタックの設定を確認して、必要に応じてスイッチCのスタックの設定を修正・保存した後、スイッチCの電源を切ります。
以下のコマンドを用いてスイッチチップに対する設定やVCSに関する設定を変更している場合は、運用中のスイッチA(マスター)と同一に設定します。
同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
バーチャルMACアドレス機能は、stack enableコマンドでVCS機能を有効化すると自動的に有効化されます。stack virtual-macコマンドをno形式で実行することにより無効化もできますが、VCS使用時は必ずバーチャルMACアドレス機能を有効にした状態で運用してください。無効状態での運用はサポート対象外となります。
上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチAと同一に設定してください。
% The device needs to be restarted for this change to take effect.
以下の例では、 ルーティングテーブル用メモリー領域をすべてIPv4に割り当て、 VCS管理用VLAN 4000、VCS管理用サブネットアドレス 172.21.255.64、バーチャルシャーシID 127(0x07f)と仮定しています。
awplus(config)# platform routingratio ipv4only ↓
awplus(config)# stack management vlan 4000 ↓
awplus(config)# stack management subnet 172.21.255.64 ↓
awplus(config)# stack virtual-mac ↓
awplus(config)# stack virtual-chassis-id 127 ↓
初期設定のままであれば、何もせずにスイッチCの電源を切ります。
- スイッチCのスタックモジュールにスタックケーブルを接続し、スイッチBに接続されていた拡張モジュールをスイッチCに装着しなおします。さらに、起動状況を確認するため、コンソールケーブルをスイッチCに接続した上で、スイッチCの電源を入れます。
- スイッチCが起動し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、スイッチCはスレーブとしてVCSグループに加わります。
- スイッチBに接続されていたケーブル類を以前と同じ構成になるように注意しながらスイッチCに接続します。
スタックリンク障害
スタックリンク(スタックモジュールまたは両方のスタックケーブル)に障害が発生した場合は、前述のとおり、レジリエンシーリンク経由のヘルスチェックでマスターの健在を認識しているスレーブがすべてのスイッチポートを無効化して、他の機器からVCSグループへのトラフィックがすべてマスターに向けられるようにします。
トラフィックの経路が完全に切り替わるとネットワークはまた以前のように動作しはじめますが、このままでは利用可能な帯域が半減していますし、冗長性も失われたままとなりますので、通常の運用では、障害の発生したスタックモジュールやケーブルを交換して、VCSグループを2台構成に復旧させる必要があります。
スタックリンク障害の場合、どの箇所で障害が起こったかによって、対処方法が異なります。以下では、障害箇所ごとの復旧手順を解説します。
片方のスタックケーブルに障害が発生した場合
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、片方のスタックケーブルに障害が発生した場合は、次の手順で復旧作業を行います。
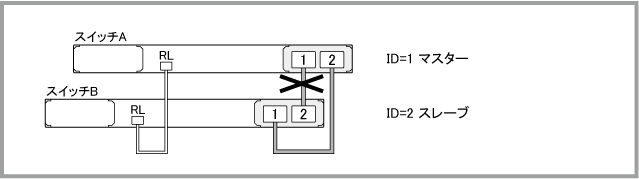
片方のスタックケーブルに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「Link down event on stack link 1.2.1」はマスター側スタックポートのリンクダウンを、「Link down event on stack link 2.2.2」はスレーブ側スタックポートのリンクダウンを表しています。
2010 Jun 11 10:45:56 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1
2010 Jun 11 10:45:56 local6.notice awplus-2 VCS[1037]: Link down event on stack link 2.2.2
また、show stackコマンドをdetailオプション付きで実行すると、次のように片方のスタックポートがリンクダウンしていることを確認できます。
awplus# sh stack detail ↓
...(中略)...
Stack member 1:
------------------------------------------------------------------
ID 1
...(中略)...
Port stk1.2.1 status Down
Port stk1.2.2 status Learnt neighbor 2
Stack member 2:
------------------------------------------------------------------
ID 2
...(中略)...
Port stk2.2.1 status Learnt neighbor 1
Port stk2.2.2 status Down
片方のスタックケーブルに障害が発生した場合は、次の手順で復旧作業を行います。
- スイッチA、Bのスタックモジュールから、障害の発生したスタックケーブルを取り外します。このときスイッチA、Bの電源を切る必要はありません。
- 新しいスタックケーブルをスイッチA、Bのスタックモジュールに接続します。これにより、復旧作業は完了です。
両方のスタックケーブルに障害が発生した場合
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、両方のスタックケーブルに障害が発生した場合は、次の手順で復旧作業を行います。
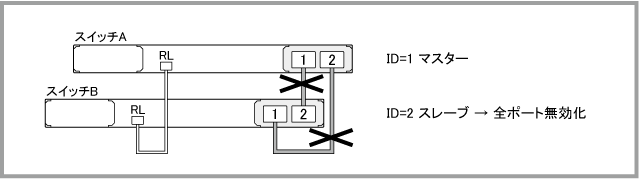
両方のスタックケーブルに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「Link down event on stack link 1.2.2」と「Link down event on stack link 1.2.1」はマスター側スタックポートのリンクダウンを、「Link down event on stack link 2.2.1」はスレーブ側スタックポートのリンクダウンを表しています。両方のスタックケーブルに障害が発生したとき、スレーブ側スタックポートのリンクダウンイベントは片方しかログに記録されません。また、「Member 2 (0009.41fb.cfaf) has left stack」は、スタックリンクの切断により、もはやスイッチB(ID=2)が同一VCSグループを構成していないことを示します。
2010 Jun 11 11:01:36 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1
2010 Jun 11 11:01:36 local6.notice awplus-2 VCS[1034]: Link down event on stack link 2.2.2
2010 Jun 11 11:01:37 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.2
2010 Jun 11 11:01:37 local6.notice awplus-2 VCS[1034]: Link down event on stack link 2.2.1
2010 Jun 11 11:01:37 user.notice awplus VCS[1034]: Link between members 1 and 2 is down
2010 Jun 11 11:01:37 local6.err awplus EXFX[1262]: Stack transport: Connection reset by peer
2010 Jun 11 11:01:37 user.crit awplus VCS[1034]: Member 2 (0009.41fb.cfaf) has left stack
2010 Jun 11 11:01:37 user.crit awplus NSM[1037]: Removal event on unit 2.0 has been completed
また、show stackコマンドでメンバーの情報を確認すると、次のようにマスターとして動作しているスイッチA(ID=1)だけがActiveと表示されます。
awplus# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0009.41fb.c7eb 128 Ready Active Master
2 - - - - Provisioned
Operational Status Standalone unit
Stack MAC address 0009.41fb.c7eb
さらに、show stackコマンドをdetailオプション付きで実行すると、次のようにマスター(ID=1)の情報だけが表示され、両方のスタックポートがリンクダウンしていることを確認できます。
vcg# show stack detail ↓
...(中略)...
Stack member 1:
------------------------------------------------------------------
ID 1
...(中略)...
Port 1.2.1 status Down
Port 1.2.2 status Down
両方のスタックケーブルに障害が発生した場合は、次の手順で復旧作業を行います。
- スイッチA(マスター)とスイッチB(スレーブ)のスタックモジュールから障害の発生したスタックケーブルを取り外します。このときスイッチA、Bの電源を切る必要はありません。これにより、VCSグループが2つに分断されてスイッチBの全ポートがリンクダウンし、マスターのスイッチAだけでVCSグループとしての動作が継続されます。
- スイッチBにコンソールケーブルを接続した上で、新しいスタックケーブルをスイッチA、Bのスタックモジュールに接続します。これにより、スイッチBが自動で再起動します。
- スイッチBの再起動が完了し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、障害発生前と同様スイッチAがマスター、スイッチBがスレーブの構成でVCSグループが動作を再開します。これにより、復旧作業は完了です。
マスターのスタックモジュールに障害が発生した場合
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、マスターであるスイッチAのスタックモジュールに障害が発生した場合、VCSグループは次の構成に移行します。
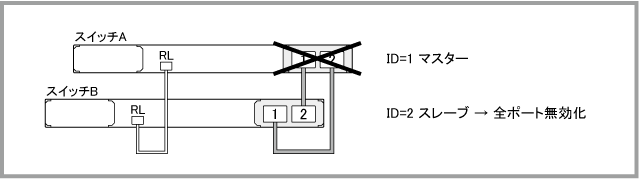
マスターのスタックモジュールに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「XEM-STK in bay 1.2 has been removed」は、マスターのスタックモジュールが取り外されたという意味ですが、ここでは障害発生を表します。続く2つの「Link down event on stack link 1.2.x」はマスター側スタックポートのリンクダウンを、「Link between members 1 and 2 is down」はマスター側スタックリンクのダウンを表しています。また、「Member 2 (0009.41fb.cfaf) has left stack」は、スタックリンクの切断により、もはやスイッチB(ID=2)が同一VCSグループを構成していないことを示します。
2010 Jun 14 18:25:45 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1
2010 Jun 14 18:25:46 user.err awplus VCS[1034]: Stack member 2 has become unreachable via Layer-2 traffic
2010 Jun 14 18:25:47 user.notice awplus VCS[1034]: Link between members 1 and 2 is down
2010 Jun 14 18:25:47 user.crit awplus VCS[1034]: Member 2 (0009.41fb.cfaf) has left stack
2010 Jun 14 18:25:47 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.2
2010 Jun 14 18:25:47 local6.err awplus EXFX[1303]: Stack transport: Connection reset by peer
2010 Jun 14 18:25:47 user.crit awplus NSM[1037]: Removal event on unit 2.0 has been completed
また、show stackコマンドでメンバーの情報を確認すると、次のようにマスターとして動作しているスイッチA(ID=1)だけがActiveと表示されます。
awplus# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0009.41fb.c7eb 128 Ready Active Master
2 - - - - Provisioned
Operational Status Standalone unit
Stack MAC address 0009.41fb.c7eb
続いて、旧スレーブが「Disabled Master」として動作しています。Disabled Master上でshow stackコマンドでメンバー情報を確認すると、次のようにスイッチB(ID=2)だけがReadyと表示され、Disable Masterと表示されます。
awplus# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - - - - Provisioned
2 - 0009.41fb.cfaf 128 Ready Disabled Master
Operational Status Operating in failover mode
Stack MAC address 0009.41fb.cfaf
マスターのスタックモジュールに障害が発生した場合は、スレーブ側が全ポートを無効化することにより、他の機器からVCSグループへのトラフィックがすべてマスターに向けられるようになります。
SwitchBlade x908における復旧手順
SwitchBlade x908ではスタック接続に本体背面の広帯域スタックポートを使用するため、スタックモジュールだけの交換はできません。「マスターが動作を停止した場合」を参照して、マスターを代替機と交換してください。したがって、このケースでは通信を停止せずに復旧することはできません。
SwitchBlade x908バージョン5.4.3-0.2以降では、広帯域スタックポートによるスタック接続のみがサポート対象で、スタックモジュール(AT-XEM-STK)はサポートしなくなりました。
スレーブのスタックモジュールに障害が発生した場合
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、スレーブであるスイッチBのスタックモジュールに障害が発生した場合は、次の手順で復旧作業を行います。
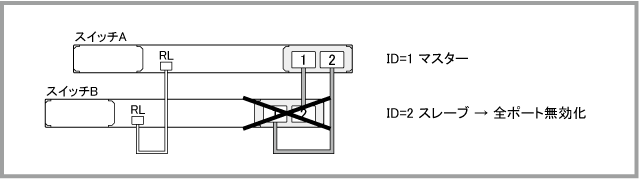
スレーブのスタックモジュールに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。マスターのスタックモジュールに障害が発生したときに表示されていた「XEM-STK in bay 1.2 has been removed」は、スレーブのスタックモジュールに障害が発生したときは表示されません。「Link down event on stack link 1.2.x」はマスター側スタックポートのリンクダウンを、「Link between members 1 and 2 is down」はマスター側スタックリンクのダウンを表しています。また、「Member 2 (0009.41fb.cfaf) has left stack」は、スタックリンクの切断により、もはやスイッチB(ID=2)が同一VCSグループを構成していないことを示します。
2010 Jun 14 19:47:45 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.1
2010 Jun 14 19:47:45 local6.err awplus EXFX[1303]: Stack transport: Connection reset by peer
2010 Jun 14 19:47:45 local6.notice awplus VCS[1034]: Link down event on stack link 1.2.2
2010 Jun 14 19:47:45 user.notice awplus VCS[1034]: Link between members 1 and 2 is down
2010 Jun 14 19:47:45 user.crit awplus NSM[1037]: Removal event on unit 2.0 has been completed
2010 Jun 14 19:47:45 user.crit awplus VCS[1034]: Member 2 (0009.41fb.cfaf) has left stack
スレーブのスタックモジュールに障害が発生した場合、show stackコマンドを実行すると次のようにマスターであるスイッチA(ID=1)の情報だけがActiveと表示されます。
awplus# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0009.41fb.c7eb 128 Ready Active Master
2 - - - - Provisioned
Operational Status Standalone unit
Stack MAC address 0009.41fb.c7eb
SwitchBlade x908における復旧手順
SwitchBlade x908ではスタック接続に本体背面の広帯域スタックポートを使用するため、スタックモジュールだけの交換はできません。「スレーブが動作を停止した場合」を参照して、スレーブを代替機と交換してください。
SwitchBlade x908バージョン5.4.3-0.2以降では、広帯域スタックポートによるスタック接続のみがサポート対象で、スタックモジュール(AT-XEM-STK)はサポートしなくなりました。
レジリエンシーリンク障害
レジリエンシーリンク障害の場合、どの箇所で障害が起こったかによって、対処方法が異なります。以下では、障害箇所ごとの復旧手順を解説します。
マスターのレジリエンシーリンク用ポートに障害が発生した場合
マスターのレジリエンシーリンク用ポート(eth0またはスイッチポート)に障害が発生した場合は、VCSグループの動作自体には影響がありません。スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、マスターであるスイッチAのレジリエンシーリンク用ポートが故障しても、VCSグループとしての動作には変化はありません。
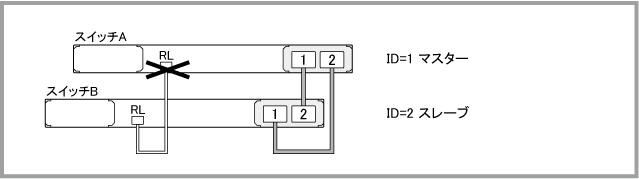
マスターのレジリエンシーリンク用ポートに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「Port down notification received for eth0」は、マスターのレジリエンシーリンクがダウンしたことを示しています。また、「Resiliency link healthchecks have failed, but master is still online」は、スレーブ側でヘルスチェックメッセージを4回連続受信できなかったが、スタックリンクは正常なため、マスターは健在であると認識できていることを示しています。
2010 Jun 14 20:04:49 user.warning awplus NSM[1037]: Port down notification received for eth0
2010 Jun 14 20:04:51 local6.err awplus-2 VCS[1039]: Resiliency link healthchecks have failed, but master is still online
レジリエンシーリンクに障害が発生した場合、show stackコマンドにdetailオプションを付けて実行すると、スレーブの「Resiliency link」欄に「Failed」と表示されます。
awplus# show stack detail ↓
...(中略)...
Stack member 2:
------------------------------------------------------------------
ID 2
Pending ID -
MAC address 0009.41fd.c285
Last role change Tue Jun 29 07:34:40 2010
Product type SwitchBlade x908
Role Backup Member
Status Ready
Priority 20
Host name awplus-2
S/W version auto synchronization On
Resiliency link Failed
Port stk2.2.1 status Learnt neighbor 1
Port stk2.2.2 status Learnt neighbor 1
このように、レジリエンシーリンクがダウンしても、ネットワークの運用には直接影響がありませんが、このままではスタックリンク障害の発生時にスレーブがマスターの存在を確認できず、両方のスイッチがマスターとして動作してしまう可能性がありますので、適切な時機を見計らって、スイッチAをVCSグループから取り外し、代わりのスイッチ(以下ではスイッチCと呼びます)を再接続する必要があります。以下、そのための手順を説明します(マスター障害発生時とほぼ同じです)。
- スイッチA(旧マスター)の電源を切ります。これによりスイッチBがマスターに昇格します。
- スイッチAのスタックモジュールからスタックケーブルを取り外します。
- スイッチAからスタックモジュールを取り外します。
- スイッチC(スイッチAの代替機)を単体起動し、ファームウェアバージョン統一などの初期設定を行います(導入編を参照)。
- スイッチCにスタックモジュールを取り付け、スタックケーブルは接続せずに起動します。
- スタックモジュール上の ID LED を見てスイッチCのID を確認します。 ID=1 であれば、スイッチAと同じなので特に何もする必要はありません。 ID=1 でない場合は、スタックモジュール上のセレクトボタンを押してスイッチC をID=1 にします。セレクトボタンを押した後は自動的に再起動するので、 起動が完了してID=1 になったことを確認します。
運用しているスタックの設定を確認して、必要に応じてスイッチCのスタックの設定を修正・保存した後、スイッチCの電源を切ります。
以下のコマンドを用いてスイッチチップに対する設定やVCSに関する設定を変更している場合は、運用中のスイッチBと同一に設定します。
同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
バーチャルMACアドレス機能は、stack enableコマンドでVCS機能を有効化すると自動的に有効化されます。stack virtual-macコマンドをno形式で実行することにより無効化もできますが、VCS使用時は必ずバーチャルMACアドレス機能を有効にした状態で運用してください。無効状態での運用はサポート対象外となります。
上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチBと同一に設定してください。
% The device needs to be restarted for this change to take effect.
以下の例では、 ルーティングテーブル用メモリー領域をすべてIPv4に割り当て、 VCS管理用VLAN 4000、VCS管理用サブネットアドレス 172.21.255.64、バーチャルシャーシID 127(0x07f)と仮定しています。
awplus(config)# platform routingratio ipv4only ↓
awplus(config)# stack management vlan 4000 ↓
awplus(config)# stack management subnet 172.21.255.64 ↓
awplus(config)# stack virtual-mac ↓
awplus(config)# stack virtual-chassis-id 127 ↓
初期設定のままであれば、何もせずにスイッチCの電源を切ります。
- スイッチCのスタックモジュールにスタックケーブルを接続し、スイッチAに接続されていた拡張モジュールをスイッチCに装着しなおします。さらに、起動状況を確認するため、コンソールケーブルをスイッチCに接続した上で、スイッチCの電源を入れます。
- スイッチCが起動し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、スイッチCはスレーブとしてVCSグループに加わります。
- スイッチAに接続されていたケーブル類を以前と同じ構成になるように注意しながらスイッチCに接続します。この結果、VCSグループの構成は次のようになります。
スレーブのレジリエンシーリンク用ポートに障害が発生した場合
スレーブのレジリエンシーリンク用ポート(eth0またはスイッチポート)に障害が発生した場合は、VCSグループの動作自体には影響がありません。スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、スレーブであるスイッチBのレジリエンシーリンク用ポートが故障しても、VCSグループとしての動作には変化はありません。
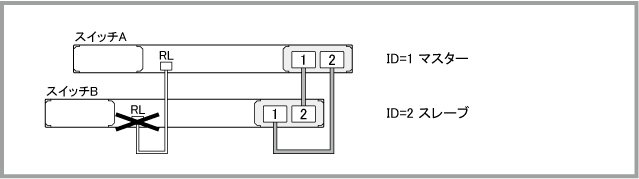
スレーブのレジリエンシーリンク用ポートに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「Resiliency link healthchecks have failed, but master is still online」は、スレーブ側でヘルスチェックメッセージを4回連続受信できなかったが、スタックリンクは正常なため、マスターは健在であると認識できていることを示しています。
2010 Jun 14 20:29:07 local6.err awplus-2 VCS[1039]: Resiliency link healthchecks have failed, but master is still online
このように、レジリエンシーリンクがダウンしても、ネットワークの運用には直接影響がありませんが、このままではスタックリンク障害の発生時にスレーブがマスターの存在を確認できず、両方のスイッチがマスターとして動作してしまう可能性がありますので、適切な時機を見計らって、スイッチBをVCSグループから取り外し、代わりのスイッチ(以下ではスイッチCと呼びます)を再接続する必要があります。以下、そのための手順を説明します(スレーブ障害発生時とほぼ同じです)。
- スイッチB(旧スレーブ)の電源を切ります。
- スイッチBのスタックモジュールからスタックケーブルを取り外します。
- スイッチBからスタックモジュールを取り外します。
- スイッチC(スイッチBの代替機)を単体起動し、ファームウェアバージョン統一などの初期設定を行います(導入編を参照)。
- スイッチCにスタックモジュールを取り付け、スタックケーブルは接続せずに起動します。
- スタックモジュール上の ID LED を見てスイッチCのID を確認します。 ID=1 であれば、スイッチAと同じなので特に何もする必要はありません。 ID=1 でない場合は、スタックモジュール上のセレクトボタンを押してスイッチC をID=1 にします。セレクトボタンを押した後は自動的に再起動するので、 起動が完了してID=1 になったことを確認します。
運用しているスタックの設定を確認して、必要に応じてスイッチCのスタックの設定を修正・保存した後、スイッチCの電源を切ります。
以下のコマンドを用いてスイッチチップに対する設定やVCSに関する設定を変更している場合は、運用中のスイッチAと同一に設定します。
同一ネットワーク上に複数のVCSグループが存在するときは、該当するVCSグループ間でバーチャルシャーシID(stack virtual-chassis-id)が重複しないよう注意して設定してください。バーチャルシャーシIDは、show stackコマンドをdetailオプション付きで実行したときに表示される「Virtual Chassis ID」欄で確認できます。
バーチャルMACアドレス機能は、stack enableコマンドでVCS機能を有効化すると自動的に有効化されます。stack virtual-macコマンドをno形式で実行することにより無効化もできますが、VCS使用時は必ずバーチャルMACアドレス機能を有効にした状態で運用してください。無効状態での運用はサポート対象外となります。
上記コマンド以外にも設定変更時に以下のメッセージが表示されるコマンドにつきましても同様に運用中のスイッチAと同一に設定してください。
% The device needs to be restarted for this change to take effect.
以下の例では、 ルーティングテーブル用メモリー領域をすべてIPv4に割り当て、 VCS管理用VLAN 4000、VCS管理用サブネットアドレス 172.21.255.64、バーチャルシャーシID 127(0x07f)と仮定しています。
awplus(config)# platform routingratio ipv4only ↓
awplus(config)# stack management vlan 4000 ↓
awplus(config)# stack management subnet 172.21.255.64 ↓
awplus(config)# stack virtual-mac ↓
awplus(config)# stack virtual-chassis-id 127 ↓
初期設定のままであれば、何もせずにスイッチCの電源を切ります。
- スイッチCのスタックモジュールにスタックケーブルを接続し、スイッチBに接続されていた拡張モジュールをスイッチCに装着しなおします。さらに、起動状況を確認するため、コンソールケーブルをスイッチCに接続した上で、スイッチCの電源を入れます。
- スイッチCが起動し、コンソール画面にログインプロンプトが表示されたことを確認します。これにより、スイッチCはスレーブとしてVCSグループに加わります。
- スイッチBに接続されていたケーブル類を以前と同じ構成になるように注意しながらスイッチCに接続します。この結果、VCSグループの構成は次のようになります。
UTPケーブルに障害が発生した場合
レジリエンシーリンクを構成するUTPケーブルに障害が発生した場合は、VCSグループの動作自体には影響がありません。スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、スイッチA、B間をつなぐUTPケーブルに障害が発生しても、VCSグループとしての動作には変化はありません。
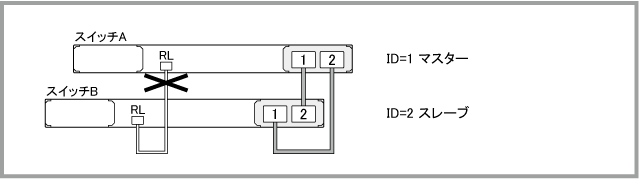
UTPケーブルに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「Port down notification received for eth0」は、マスターのレジリエンシーリンクがダウンしたことを示しています。また、「Resiliency link healthchecks have failed,but master is still online」は、スレーブ側でヘルスチェックメッセージを4回連続受信できなかったが、スタックリンクは正常なため、マスターは健在であると認識できていることを示しています。
2010 Jun 14 20:04:49 user.warning awplus NSM[1037]: Port down notification received for eth0
2010 Jun 14 20:04:51 local6.err awplus-2 VCS[1039]: Resiliency link healthchecks have failed, but master is still online
このように、レジリエンシーリンクがダウンしても、ネットワークの運用には直接影響がありませんが、このままではスタックリンク障害の発生時にスレーブがマスターの存在を確認できず、両方のスイッチがマスターとして動作してしまう可能性がありますので、以下の手順にしたがってUTPケーブルを交換してください。
- スイッチA、Bのレジリエンシーリンク用ポート(eth0またはスイッチポート)から、障害の発生したUTPケーブルを取り外します。このときスイッチA、Bの電源を切る必要はありません。
- 新しいUTPケーブルをスイッチA、Bのレジリエンシーリンク用ポート(eth0またはスイッチポート)に接続します。これにより、復旧作業は完了です。
ポート増設用拡張モジュール障害
ポート増設用拡張モジュールの障害は、VCSグループの運用に直接的な影響を与えることはありませんが、該当モジュール上のポートが使えなくなるなどの間接的な影響があるため、通常の運用では交換が必要です。
マスターのポート増設用拡張モジュールに障害が発生した場合
マスターのポート増設用拡張モジュールに発生する障害としては、おもに次の2種類が考えられます。
- 拡張モジュール自体が故障し、認識されなくなる
- 拡張モジュールのステータス異常(ファン回転数異常など)が検出される
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、マスターのポート増設用拡張モジュールが故障して認識されなくなった場合、show logコマンドでログを確認すると、次のように表示されます。「HOTSWAP XEM 1 hotswapped out: XEM-12T」、「Handle event: bay 1 hsState4 bt 274 br 0」、「Removal event on bay 1.1 has been completed」などは、いずれもマスターの拡張モジュールが取り外された、すなわち、ここでは故障により認識できなくなったことを示しています。
2010 Jun 15 19:23:02 daemon.crit awplus HPI: HOTSWAP XEM 1 hotswapped out: XEM-12T
2010 Jun 15 19:23:02 local6.crit awplus EXFX[1192]: Handle event: bay 1 hsState 4 bt 274 br 0
2010 Jun 15 19:23:02 user.crit awplus NSM[1037]: Removal event on bay 1.1 has been completed
拡張モジュールが障害のため認識されていないことは、show systemコマンドの製品(部品)一覧に該当モジュールが表示されないことや、拡張モジュール上のLEDが点灯しないことによっても判別できます。
また、マスターのポート増設用拡張モジュール上の冷却ファンに異常が検出された場合は、show logコマンドでログを確認すると、次のように表示されます。「SENSOR XEM 1 - Fan: XEM Fan 1: Reading 0 Rpm below minimum 3516 Rpm」は、拡張モジュール上のファン回転数が監視用の下限しきい値を下回った、すなわち、冷却ファンの異常を検出したことを示しています。
2008 Jan 18 12:26:53 daemon.crit vcg HPI: SENSOR XEM 1 - Fan: XEM Fan 1: Reading 0 Rpm below minimum 3516 Rpm
拡張モジュール上のステータス異常(ファン障害)が検出されているときは、show systemコマンドの「Environment Status」欄が「**Fault**」になります。また、show system environmentコマンドの出力では、スイッチAの「Overall Status」欄が「**Fault**」、拡張モジュールの「Fan: XEM Fan X」の「Status」欄が「FAULT」になり、さらにスイッチAのFAULT LEDが赤く点滅します。
なお、いずれの場合も、ポート増設用拡張モジュールの障害はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力から拡張モジュールの障害を知ることはできません。
マスターのポート増設用拡張モジュールを交換するときは、以下の手順にしたがってください。
- いずれかのスイッチ にコンソールケーブルを接続した上で、スイッチA(マスター)の故障した拡張モジュールに接続されているケーブル類を取り外します。
- スイッチA の故障した拡張モジュールをホットスワップで取り外します(注:AT-SBx908でAT-XEM-12S/12Sv2を使用しているときは、SFPをすべて取り外してからAT-XEM-12S/12Sv2を取り外してください)。
- スイッチA の同じ拡張ベイに新しい拡張モジュールをホットスワップで取り付けます(注:AT-SBx908でAT-XEM-12S/12Sv2を使用しているときは、SFPをすべて取り外した状態でAT-XEM-12S/12Sv2を取り付けてください)。
- コンソール画面に「Configuration update completed for portA.B.Y-A.B.Z」のようなメッセージが出力されたことを確認した後、該当拡張モジュールにSFP/SFP+/XFPモジュールやケーブルをもとどおり接続します。これにより、復旧作業は完了です。
なお、マスターのポート増設用拡張モジュールを交換するときは、以下の点に注意してください。
- 手順2~3において、SwitchBlade x908でAT-XEM-12S/12Sv2をホットスワップするときは、AT-XEM-12S/12Sv2からSFPをすべて取り外した状態で、AT-XEM-12S/12Sv2の取り外し・取り付けを行ってください。
- ハードウェアヘルスチェックモニタリング機能、スイッチチップポーリング機能において、異常を検知した拡張モジュールを自動的に無効化する機能を有効化している場合(system hw-monitoring shutdownコマンド、system hw-monitoring pcsping power-offコマンドを設定している場合)、同機能によって無効化された拡張モジュールのホットスワップはできません。詳細は前記コマンドページの「注意・補足事項」をご覧ください。
- 拡張モジュールの交換時には、以下の通信停止期間が発生します。
- マスター側の故障した拡張モジュールポート
(モジュール自体が故障して認識されなくなったとき)障害発生時から、手順4で拡張モジュールにケーブルを再接続するまで
(モジュールのステータス異常が検出されたとき)手順1で故障した拡張モジュールのケーブルを抜いてから、手順4で正常な拡張モジュールにケーブルを再接続するまで
- マスター側のスイッチポート(故障した拡張モジュールポートを除く)
停止しない
- スレーブ側の全スイッチポート
停止しない
スレーブのポート増設用拡張モジュールに障害が発生した場合
スレーブのポート増設用拡張モジュールに発生する障害としては、おもに次の2種類が考えられます。
- 拡張モジュール自体が故障し、認識されなくなる
- 拡張モジュールのステータス以上(ファン回転数異常など)が検出される
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、スレーブのポート増設用拡張モジュールに障害が発生した後、show logコマンドでログを確認すると、次のように表示されます。「HOTSWAP XEM 1 hotswapped out: XEM-12T」、「Handle event: bay 1 hsState 4 bt 274 br 0」、「Removal event on bay 2.1 has been completed」などは、いずれもスレーブの拡張モジュールが取り外されたことを示しています。
20:49:25 awplus-2 HPI: HOTSWAP XEM 1 hotswapped out: XEM-12T
20:49:25 awplus-2 EXFX[1196]: Handle event: bay 1 hsState 4 bt 274 br 0
20:49:25 awplus NSM[1037]: Removal event on bay 2.1 has been completed
拡張モジュールが障害のため認識されていないことは、show systemコマンドの製品(部品)一覧に該当モジュールが表示されないことや、拡張モジュール上のLEDが点灯しないことによっても判別できます。
また、スレーブのポート増設用拡張モジュール上の冷却ファンに異常が検出された場合は、show logコマンドでログを確認すると、次のように表示されます。「SENSOR XEM 1 - Fan: XEM Fan 1: Reading 0 Rpm below minimum 3516 Rpm」は、拡張モジュール上のファン回転数が監視用の下限しきい値を下回った、すなわち、冷却ファンの異常を検出したことを示しています。
2008 Jan 21 02:36:11 daemon.crit vcg-2 HPI: SENSOR XEM 1 - Fan: XEM Fan 1: Reading 0 Rpm below minimum 3516 Rpm
拡張モジュールのステータス異常(ファン障害)が検出されているときは、show systemコマンドの「Environment Status」欄が「**Fault**」になります。また、show system environmentコマンドの出力では、スイッチBの「Overall Status」欄が「**Fault**」、拡張モジュールの「Fan: XEM Fan X」の「Status」欄が「FAULT」になり、さらにスイッチBのFAULT LEDが赤く点滅します。
なお、いずれの場合も、ポート増設用拡張モジュールの障害はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力から拡張モジュールの障害を知ることはできません。
スレーブのポート増設用拡張モジュールを交換するときは、以下の手順にしたがってください。
- いずれかのスイッチにコンソールケーブルを接続した上で、スイッチB(スレーブ)の故障した拡張モジュールに接続されているケーブル類を取り外します。
- スイッチBの故障した拡張モジュールをホットスワップで取り外します(注:AT-SBx908でAT-XEM-12S/12Sv2を使用しているときは、SFPをすべて取り外してからAT-XEM-12S/12Sv2を取り外してください)。
- スイッチBの同じ拡張ベイに新しい拡張モジュールをホットスワップで取り付けます(注:AT-SBx908でAT-XEM-12S/12Sv2を使用しているときは、SFPをすべて取り外した状態でAT-XEM-12S/12Sv2を取り付けてください)。
- コンソール画面に「Configuration update completed for portA.B.Y-A.B.Z」のようなメッセージが出力されたことを確認した後、該当拡張モジュールにSFP/SFP+/XFPモジュールやケーブルをもとどおり接続します。これにより、復旧作業は完了です。
なお、スレーブのポート増設用拡張モジュールを交換するときは、以下の点に注意してください。
- 手順2~3において、SwitchBlade x908でAT-XEM-12S/12Sv2をホットスワップするときは、AT-XEM-12S/12Sv2からSFPをすべて取り外した状態で、AT-XEM-12S/12Sv2の取り外し・取り付けを行ってください。
- ハードウェアヘルスチェックモニタリング機能、スイッチチップポーリング機能において、異常を検知した拡張モジュールを自動的に無効化する機能を有効化している場合(system hw-monitoring shutdownコマンド、system hw-monitoring pcsping power-offコマンドを設定している場合)、同機能によって無効化された拡張モジュールのホットスワップはできません。詳細は前記コマンドページの「注意・補足事項」をご覧ください。
- 拡張モジュールの交換時には、以下の通信停止期間が発生します。
- スレーブ側の故障した拡張モジュールポート
(モジュール自体が故障して認識されなくなったとき)障害発生時から、手順4で拡張モジュールにケーブルを再接続するまで
(モジュールのステータス異常が検出されたとき)手順1で故障した拡張モジュールのケーブルを抜いてから、手順4で正常な拡張モジュールにケーブルを再接続するまで
- スレーブ側のスイッチポート(故障した拡張モジュールポートを除く)
停止しない
- マスター側の全スイッチポート
停止しない
電源ユニット障害
電源ユニット(AT-PWR01-70、AT-PWR05-70)の障害は、おもに次の2種類が考えられます。
- 電源ユニット自体が故障する
- 電源ユニットのステータス異常(ファン回転数異常など)が検出される
電源ユニット自体が故障した場合
電源ユニット自体が故障した場合は、電源を冗長化しているかどうかによって対応方法が異なります。以下、それぞれのケースについて対応方法を説明します。
電源を冗長化していない場合
電源を冗長化していない場合、電源ユニットの故障は電源断、すなわち、スイッチ本体の動作停止をまねきます。
- マスターの電源ユニットに障害が発生した場合
マスターの電源ユニットが故障した場合のVCSグループの動作や障害検出方法については、「マスターが動作を停止した場合」をご参照ください。
マスターの電源ユニットを交換するときは、次の手順にしたがってください(電源ユニットの詳細な交換手順については、取扱説明書をご覧ください)。
- スイッチA(旧マスター)から故障した電源ユニットを取り外し、正常な電源ユニットを取り付けて電源ケーブルを接続します。これにより、スイッチAはスレーブとしてVCSグループに復帰し、以前とは異なりスイッチBがマスター、スイッチAがスレーブの構成になります。
- スレーブの電源ユニットに障害が発生した場合
スレーブの電源ユニットが故障した場合のVCSグループの動作や障害検出方法については、「スレーブが動作を停止した場合」をご参照ください。
スレーブの電源ユニットを交換するときは、次の手順にしたがってください(電源ユニットの詳細な交換手順については、取扱説明書をご覧ください)。
- スイッチB(スレーブ)から故障した電源ユニットを取り外し、正常な電源ユニットを取り付けて電源ケーブルを接続します。これにより、スイッチBはスレーブとしてVCSグループに復帰し、以前と同じようにスイッチAがマスター、スイッチBがスレーブの構成になります。
電源を冗長化している場合
電源を冗長化している場合、電源ユニットが1台故障してもVCSグループの運用には影響がありませんが、このままでは電源の冗長性が失われたままとなりますので、以下の手順で故障した電源ユニットを交換してください。なお、この場合の対応方法はマスター・スレーブ共通です。
(以下ではマスターの電源ユニットに障害が発生したケースを例としていますが、スレーブの場合も同様です。適宜スイッチ名やIDを読み替えてください)。
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、マスターの電源ユニットの1台が故障した場合、show logコマンドでログを確認すると、次のように表示されます。「SENSOR PSU slot 2 - Device Present: BAD」、「HOTSWAP PSU 2 hotswapped out: AT-PWR01」は、いずれもマスターの電源ユニットの1つが取り外された、すなわち、ここでは故障により認識できなくなったことを示しています。
2008 Jan 21 09:42:23 daemon.crit vcg HPI: SENSOR PSU slot 2 - Device Present: BAD
2008 Jan 21 09:42:26 daemon.crit vcg HPI: HOTSWAP PSU 2 hotswapped out: AT-PWR01-AC
電源ユニットの1台が障害のため認識されていないことは、show systemコマンドの製品(部品)一覧に該当電源ユニットが表示されないことや、同じくshow systemコマンドの「Environment Status」欄が「**Fault**」になることからわかります。また、show system environmentコマンドの出力では、スイッチAの「Overall Status」欄が「**Fault**」、該当電源ユニットの「Device Present」の「Status」欄が「FAULT」になり、さらにスイッチAのPSU X LED(Xは該当電源ユニットを装着したスロットの番号)が赤く点灯します。
電源を冗長化している場合、電源ユニット1台の障害はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力から該当電源ユニットの障害を知ることはできません。
電源を冗長化している場合に電源ユニットの1台を交換するときは、以下の手順にしたがってください(電源ユニットの詳細な交換手順については、取扱説明書をご覧ください)。
- スイッチA(マスター)から故障した電源ユニットを取り外し、正常な電源ユニットを取り付けて電源ケーブルを接続します。これにより、VCSグループの構成や通信に影響を与えることなく、電源ユニットの交換が完了します。
電源ユニットのステータス異常が検出された場合
マスターの電源ユニットにステータス異常(ファン障害など)が検出された場合は、show logコマンドでログを確認すると、次のように表示されます。「SENSOR PSU slot 2 - PSU Fan Fail: BAD」は、電源ユニットのファンに異常を検出したことを示しています。
2008 Jan 21 05:32:17 daemon.crit vcg HPI: SENSOR PSU slot 2 - PSU Fan Fail: BAD
電源ユニットのステータス異常は、show systemコマンドの「Environment Status」欄が「**Fault**」になることからわかります。また、show system environmentコマンドの出力では、スイッチAの「Overall Status」欄が「**Fault**」、該当電源ユニットの「PSU Fan Fail」の「Status」欄が「FAULT」になり、さらにスイッチAのPSU X LED(Xは該当電源ユニットを装着したスロットの番号)が赤く点灯します。
電源ユニットのステータス異常はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力から該当電源ユニットのステータス異常を知ることはできません。
電源ユニットにステータス異常(ファン障害など)が検出された場合は、電源を冗長化しているかどうかによって対応方法が異なります。以下、それぞれのケースについて対応方法を説明します。
電源を冗長化していない場合
電源を冗長化していない場合に電源ユニットにステータス異常が検出された場合は、以下の手順にしたがってください(電源ユニット/ファンモジュールの詳細な交換手順については、取扱説明書をご覧ください)。
- 該当スイッチからファンモジュールを取り外し(ステータス異常の発生した電源ユニットはそのままにしておく)、代わりに正常な電源ユニットを取り付けて電源ケーブルを接続します。
- ステータス異常の発生した電源ユニットを取り外し、手順1で取り外したファンモジュールを取り付けます。これにより、VCSグループの構成や通信に影響を与えることなく、電源ユニットの交換が完了します。
電源を冗長化している場合
電源を冗長化している場合に電源ユニットにステータス異常が検出された場合は、以下の手順にしたがってください(電源ユニット/ファンモジュールの詳細な交換手順については、取扱説明書をご覧ください)。
- 該当スイッチからステータス異常の発生した電源ユニットを取り外し、正常な電源ユニットを取り付けて電源ケーブルを接続します。これにより、VCSグループの構成や通信に影響を与えることなく、電源ユニットの交換が完了します。
ファンモジュール障害
ファンモジュール(AT-FAN01、AT-FAN03)の障害は、おもに次の2種類が考えられます。
- ファンモジュール自体が故障し、認識されなくなる
- ファンモジュールのステータス異常(ファン回転数異常など)が検出される
ファンモジュール自体が故障した場合
ファンモジュール自体が故障した場合、VCSグループの運用に直接的な影響がありませんが、このままでは内部温度が上昇してシステムが故障するおそれがありますので、以下の手順で故障したファンモジュールを交換してください。なお、この場合の対応方法はマスター・スレーブ共通です。
(以下ではマスターのファンモジュールに障害が発生したケースを例としていますが、スレーブの場合も同様です。適宜スイッチ名やIDを読み替えてください)。
スイッチA(ID=1)がマスター、スイッチB(ID=2)がスレーブの状態において、マスターのファンモジュールが故障した場合、show logコマンドでログを確認すると、次のように表示されます。「SENSOR PSU slot 2 - Device Present: BAD」、「HOTSWAP FOM 2 hotswapped out: AT-FAN01」は、いずれもマスターのファンモジュールが取り外された、すなわち、ここでは故障により認識できなくなったことを示しています。
2008 Jan 21 09:42:23 daemon.crit vcg HPI: SENSOR PSU slot 2 - Device Present: BAD
2008 Jan 21 09:42:26 daemon.crit vcg HPI: HOTSWAP FOM 2 hotswapped out: AT-FAN01
ファンモジュールの1台が障害のため認識されていないことは、show systemコマンドの製品(部品)一覧に該当ファンモジュールが表示されないことや、同じくshow systemコマンドの「Environment Status」欄が「**Fault**」になることからわかります。また、show system environmentコマンドの出力では、スイッチAの「Overall Status」欄が「**Fault**」、該当ファンモジュールの「Device Present」の「Status」欄が「FAULT」になり、さらにスイッチAのPSU X LED(Xは該当ファンモジュールを装着したスロットの番号)が赤く点灯します。
ファンモジュールの障害はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力から該当ファンモジュールの障害を知ることはできません。
ファンモジュールを交換するときは、以下の手順にしたがってください(ファンモジュールの詳細な交換手順については、取扱説明書をご覧ください)。
- 該当スイッチから故障したファンモジュールを取り外し、正常なファンモジュールを取り付けます。これにより、VCSグループの構成や通信に影響を与えることなく、ファンモジュールの交換が完了します。
ファンモジュールのステータス異常が検出された場合
マスターのファンモジュールにステータス異常(ファン回転数異常など)が検出された場合は、show logコマンドでログを確認すると、次のように表示されます。「SENSOR PSU slot 2 - PSU Fan Fail: BAD」は、ファンモジュールのファンに異常を検出したことを示しています。
2008 Jan 21 05:32:17 daemon.crit vcg HPI: SENSOR PSU slot 2 - PSU Fan Fail: BAD
ファンモジュールのステータス異常は、show systemコマンドの「Environment Status」欄が「**Fault**」になることからわかります。また、show system environmentコマンドの出力では、スイッチAの「Overall Status」欄が「**Fault**」、該当ファンモジュールの「PSU Fan Fail」の「Status」欄が「FAULT」になり、さらにスイッチAのPSU X LED(Xは該当ファンモジュールを装着したスロットの番号)が赤く点灯します。
ファンモジュールのステータス異常はVCSグループの状態には直接影響を与えないため、show stackコマンドの出力から該当ファンモジュールのステータス異常を知ることはできません。
ファンモジュールを交換するときは、以下の手順にしたがってください(ファンモジュールの詳細な交換手順については、取扱説明書をご覧ください)。
- 該当スイッチからステータス異常の発生したファンモジュールを取り外し、正常なファンモジュールを取り付けます。これにより、VCSグループの構成や通信に影響を与えることなく、ファンモジュールの交換が完了します。
メンテナンス
ファームウェアバージョンアップ
VCSグループの運用中にファームウェアをバージョンアップする場合は、次の手順にしたがってください。
ここでは説明のため、次の環境を想定します。
- マスター(ID=1)、スレーブ(ID=2)でVCSグループを運用中
- VCSグループのホスト名は「vcg」
- 現在のファームウェアバージョンは5.4.7-2.5
- 新しいファームウェアバージョンは5.4.7-2.6
- 新しいファームウェアのイメージファイルSBx908-5.4.7-2.6.relは、VCSグループからアクセス可能なTFTPサーバー10.100.10.70上に置かれている
5.4.7-2.6は説明上使用している架空のファームウェアです。5.4.7-2.5リリース時点では実在しませんのでご注意ください。
- show stackコマンドを実行し、VCSグループが正しく構築されていることを確認してください。
vcg# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0009.41fb.c7eb 128 Ready Active Master
2 - 0009.41fb.cfaf 128 Ready Backup Member
Operational Status Normal operation
Stack MAC address 0009.41fb.c7eb
- TFTPサーバー上などで、新しいファームウェアイメージファイルのサイズを確認してください。Windowsならファイルの「プロパティ」や「dir」コマンド、UNIXなら「ls -l」コマンドなどで確認します。
- show file systemsコマンドを実行して、各メンバーのフラッシュメモリー空き容量を確認します。
vcg# show file systems ↓
Stack member 1:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.2M flash rw flash: static local Y
- - system rw system: virtual local -
...
Stack member 2:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.3M flash rw flash: static local Y
- - system rw system: virtual local -
...
この例では、メンバー1の空き容量が47.2MByte、メンバー2の空き容量が47.3MByteであると確認できます。空き容量とイメージファイルのサイズを比較して、すべてのメンバーにイメージファイルを格納するのに充分な空きがあることを確認してください。
いずれかのメンバーの空き容量が足りない場合は、deleteコマンドで不要なファイルを削除して空きを作ってください。たとえば、メンバー2の空き容量が足りない場合は、次のようにして不要なファイルを削除します。
vcg# dir vcg-2/flash:/*.rel ↓
...
1401740 -rw- Jan 01 2011 00:00:00 vcg-2/flash:/SBx908-nolonger-used.rel
...
vcg# delete vcg-2/flash:/SBx908-nolonger-used.rel ↓
Deleting....................................................
Successful operation
ここで、コマンド中の「vcg-2/」はスレーブのファイルシステムを指定するための書式で、VCSグループのホスト名(例ではvcg)、半角ハイフン、スレーブのスタックメンバーID(例では2)、半角スラッシュをつなげたものです。
「vcg-2/」は一例ですので、実際にはご使用の環境におけるホスト名とスタックメンバーIDを指定してください。たとえば、VCSグループのホスト名が「november」でスレーブのスタックメンバーIDが「3」のときは、「vcg-2/」の代わりに「november-3/」と指定します。なお、ホスト名を明示的に設定していない場合、VCSグループのホスト名は「awplus」となります(たとえば、「awplus-2/」などと指定します)。
スレーブファイルシステムの指定方法については、応用編をご覧ください。
- 新しいファームウェアのイメージファイルをマスターにダウンロードします。
vcg# copy tftp://10.100.10.70/SBx908-5.4.7-2.6.rel flash ↓
Enter destination file name [SBx908-5.4.7-2.6.rel]:
Copying....................................................
Successful operation
- boot systemコマンドを使って、新しいイメージファイルを通常用ファームウェアに指定します。このコマンドを実行すると、マスター上のイメージファイルがスレーブメンバーに自動的にコピーされます。イメージファイルの設定は、コマンド実行時にシステムファイルに保存されるため、copyコマンドやwrite fileコマンド、write memoryコマンドなどでコンフィグに保存する必要はありません。
vcg# configure terminal ↓
Enter configuration commands, one per line. End with CNTL/Z.
vcg(config)# boot system SBx908-5.4.7-2.6.rel ↓
VCS synchronizing file across the stack, please wait........................
File synchronization with stack member-2 successfully completed
[DONE]
- show bootコマンドを実行して、通常用ファームウェアイメージの設定を確認します。また、各メンバーに対してdirコマンドを実行し、すべてのメンバーに新しいファームウェアのイメージファイルが存在することを確認してください。
vcg# show boot ↓
Boot configuration
--------------------------------------------------------------------------------
Current software : SBx908-5.4.7-2.5.rel
Current boot image : flash:/SBx908-5.4.7-2.6.rel
Backup boot image : Not set
Default boot config: flash:/default.cfg
Current boot config: flash:/default.cfg (file exists)
Backup boot config : Not set
Autoboot status : disabled
vcg# dir *.rel ↓
14492851 -rw- May 11 2012 06:42:05 flash:/SBx908-5.4.7-2.6.rel
...
vcg# dir vcg-2/flash:/*.rel ↓
14492851 -rw- May 11 2012 06:42:05 vcg-2/flash:/SBx908-5.4.7-2.6.rel
...
- VCSグループ全体を再起動します。
再起動中は通信断が発生します。
vcg(config)# end ↓
vcg# reload ↓
Are you sure you want to reboot the whole stack? (y/n): y ↓
...
- 再起動完了後、show systemコマンドでファームウェアバージョンを確認し、show stackコマンドでVCSグループが正しく構築されていることを確認します。問題がなければ、以上でバージョンアップは完了です。
VCSホットソフトウェアアップグレード
ファームウェアバージョン5.3.4-0.1以降では、reload rolling/reboot rollingコマンドによるVCSホットソフトウェアアップグレードを利用できます。マスターの切り替えと再起動、ファームウェアバージョンアップをメンバーごとに順番に行うため、通常のrebootコマンドを使用する場合に比べて、ファームウェアバージョンアップ時のシステム停止時間を短くすることができます。
reload rolling/reboot rollingコマンドは、5.3.3系列またはそれ以前のファームウェアに戻すときには使用できません。
reload rolling/reboot rollingコマンドは、メジャーバージョンアップには使用できません。
reload rolling/reboot rollingコマンドを使用して、VCSグループの運用中にファームウェアをバージョンアップする場合は、次の手順にしたがってください。ここでは説明のため、次の環境を想定します。(以下の説明では、実際のバージョンや画面とは異なる場合があります。)
- マスター(ID=1)、スレーブ(ID=2)でVCSグループを運用中
- VCSグループのホスト名は「vcg」
- 現在のファームウェアバージョンは5.4.7-2.5
- 新しいファームウェアバージョンは5.4.7-2.6
- 新しいファームウェアのイメージファイルSBx908-5.4.7-2.6.relは、VCSグループからアクセス可能なTFTPサーバー10.100.10.70上に置かれている
5.4.7-2.6は説明上使用している架空のファームウェアです。5.4.7-2.5リリース時点では実在しませんのでご注意ください。
- show stackコマンドを実行し、VCSグループが正しく構築されていることを確認してください。
vcg# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0009.41fb.c7eb 128 Ready Active Master
2 - 0009.41fb.cfaf 128 Ready Backup Member
Operational Status Normal operation
Stack MAC address 0009.41fb.c7eb
- TFTPサーバー上などで、新しいファームウェアイメージファイルのサイズを確認してください。Windowsならファイルの「プロパティ」や「dir」コマンド、UNIXなら「ls -l」コマンドなどで確認します。
- show file systemsコマンドを実行して、各メンバーのフラッシュメモリー空き容量を確認します。
vcg# show file systems ↓
Stack member 1:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.2M flash rw flash: static local Y
- - system rw system: virtual local -
...
Stack member 2:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 47.3M flash rw flash: static local Y
- - system rw system: virtual local -
...
この例では、メンバー1の空き容量が47.2MByte、メンバー2の空き容量が47.3MByteであると確認できます。空き容量とイメージファイルのサイズを比較して、すべてのメンバーにイメージファイルを格納するのに充分な空きがあることを確認してください。
いずれかのメンバーの空き容量が足りない場合は、deleteコマンドで不要なファイルを削除して空きを作ってください。たとえば、メンバー2の空き容量が足りない場合は、次のようにして不要なファイルを削除します。
vcg# dir vcg-2/flash:/*.rel ↓
...
1401740 -rw- Jan 01 2011 00:00:00 vcg-2/flash:/SBx908-nolonger-used.rel
...
vcg# delete vcg-2/flash:/SBx908-nolonger-used.rel ↓
Deleting....................................................
Successful operation
ここで、コマンド中の「vcg-2/」はスレーブのファイルシステムを指定するための書式で、VCSグループのホスト名(例ではvcg)、半角ハイフン、スレーブのスタックメンバーID(例では2)、半角スラッシュをつなげたものです。
「vcg-2/」は一例ですので、実際にはご使用の環境におけるホスト名とスタックメンバーIDを指定してください。たとえば、VCSグループのホスト名が「november」でスレーブのスタックメンバーIDが「3」のときは、「vcg-2/」の代わりに「november-3/」と指定します。なお、ホスト名を明示的に設定していない場合、VCSグループのホスト名は「awplus」となります(たとえば、「awplus-2/」などと指定します)。
スレーブファイルシステムの指定方法については、応用編をご覧ください。
- 新しいファームウェアのイメージファイルをマスターにダウンロードします。
vcg# copy tftp://10.100.10.70/SBx908-5.4.7-2.6.rel flash ↓
Enter destination file name [SBx908-5.4.7-2.6.rel]:
Copying....................................................
Successful operation
- boot systemコマンドを使って、新しいイメージファイルを通常用ファームウェアに指定します。このコマンドを実行すると、マスター上のイメージファイルがスレーブメンバーに自動的にコピーされます。イメージファイルの設定は、コマンド実行時にシステムファイルに保存されるため、copyコマンドやwrite fileコマンド、write memoryコマンドなどでコンフィグに保存する必要はありません。
vcg# configure terminal ↓
Enter configuration commands, one per line. End with CNTL/Z.
vcg(config)# boot system SBx908-5.4.7-2.6.rel ↓
VCS synchronizing file across the stack, please wait........................
File synchronization with stack member-2 successfully completed
[DONE]
- show bootコマンドを実行して、通常用ファームウェアイメージの設定を確認します。また、各メンバーに対してdirコマンドを実行し、すべてのメンバーに新しいファームウェアのイメージファイルが存在することを確認してください。
vcg# show boot ↓
Boot configuration
--------------------------------------------------------------------------------
Current software : SBx908-5.4.7-2.5.rel
Current boot image : flash:/SBx908-5.4.7-2.6.rel
Backup boot image : Not set
Default boot config: flash:/default.cfg
Current boot config: flash:/default.cfg (file exists)
Backup boot config : Not set
Autoboot status : disabled
vcg# dir *.rel ↓
14492851 -rw- May 11 2012 06:42:05 flash:/SBx908-5.4.7-2.6.rel
...
vcg# dir vcg-2/flash:/*.rel ↓
14492851 -rw- May 11 2012 06:42:05 vcg-2/flash:/SBx908-5.4.7-2.6.rel
...
- reload rolling/reboot rollingコマンドによりVCSグループを再起動します。
vcg# reboot rolling ↓
The stack master will reboot immediately and boot up with the configuration file settings.
The remaining stack members will then reboot once the master has finished re-configuring.
Continue the rolling reboot of the stack? (y/n): y
21:21:40 vcg VCS[1034]: Automatically rebooting stack member-1 (MAC: 0009.41fb.
c7eb) due to Rolling reboot
起動方法は以下のとおりです。
(1) マスター(ID=1)から再起動します。
(2) スレーブ(ID=2)がマスター(ID=2)として起動します。
スレーブからマスターへ遷移するとき、リンクダウンはしません。
(3) 再起動している旧マスター(ID=1)が各プロセスの起動を完了し、コンフィグを読み込んだ後に、マスター(ID=2)が再起動します。
(4) (ID=1)がマスターとして起動します。
マスター(ID=1)は正常起動するまでポートをリンクアップしません。旧マスター(ID=2)も再起動中はリンクダウンするため、マスター(ID=1)がコンフィグを読み込んでから正常起動するまでの間、一時的にVCSグループの全ポートがリンクダウンしている状態になります。
マスター(ID=1)の正常起動後にポートがリンクアップして通信が可能な状態になりますが、通信が復旧するまでの時間は、ネットワーク環境と使用しているプロトコルの復旧時間に依存します。
(5) 旧マスター(ID=2)が自動的にVCSメンバーにスレーブとして追加されます。
(6) 5.4.7-2.6にバージョンアップし、VCS再運用が可能となります。
SDカードオートブート機能を使用したファームウェアバージョンアップ
ファームウェアバージョン5.4.1-2.8 以降では、SDカードまたはSDHCカード(以後、本セクションでは原則としてSDカードと総称します)にファームウェアイメージファイルやコンフィグファイル、および、これらのファイル名を記載した設定ファイル(autoboot.txt)を格納しておき、このSDカードを装着した状態でシステムを起動することにより、ファームウェアやコンフィグファイルの更新を自動的に行う「SDカードオートブート機能」をサポートしています。
本機能はファームウェアバージョン5.4.1-2.8からサポートとなりますが、バージョンアップ時に実際に使用できるのは5.4.1-2.8よりあとのバージョンがリリースされたとき、つまり、現在のファームウェアバージョンが5.4.1-2.8以降で、新しいファームウェアバージョンが5.4.1-2.9 以降の場合となります。
SDHCカードを使用する場合は、SDHCカードを装着して起動するマスターのブートローダーバージョンが1.1.6以降である必要があります。ブートローダーバージョンはshow systemコマンドの出力結果の「Bootloader version」の項目で確認できます。
vcg# show system ↓
Stack System Status Wed Mar 02 08:05:08 2011
Stack member 1:
Board ID Bay Board Name Rev Serial number
--------------------------------------------------------------------------------
Base 281 SwitchBlade x908 C-2 C1JB9C02U
Expansion 273 Bay1 XEM-12S D-0 A1HC8207X
PSU 298 PSU1 AT-PWR05-AC B-0 100525-000B1
--------------------------------------------------------------------------------
RAM: Total: 513000 kB Free: 408220 kB
Flash: 63.0MB Used: 59.8MB Available: 3.2MB
--------------------------------------------------------------------------------
Environment Status : Normal
Uptime : 0 days 23:52:27
Bootloader version : 1.1.6
Stack member 2:
Board ID Bay Board Name Rev Serial number
--------------------------------------------------------------------------------
Base 281 SwitchBlade x908 D-2 C1JBA2018
Expansion 273 Bay1 XEM-12S D-0 A1HC8A02Q
PSU 298 PSU1 AT-PWR05-AC B-0 100525-000BY
--------------------------------------------------------------------------------
RAM: Total: 513000 kB Free: 410432 kB
Flash: 63.0MB Used: 56.6MB Available: 6.4MB
--------------------------------------------------------------------------------
Environment Status : Normal
Uptime : 0 days 22:50:33
Bootloader version : 1.1.6
SDカードオートブート機能自体は単体構成時(非VCS構成時)のみのサポートですが、下記手順にしたがって実行することにより、VCSグループのバージョンアップに利用することも可能です。
以下ではSDカードオートブート機能を使用してVCS構成の全スタックメンバーのファームウェアをバージョンアップする方法を紹介します。
なお、この方法で必要なSDカードはマスターで使用する1つだけとなります。
本機能を使用してファームウェアをバージョンアップする場合は次の手順にしたがってください。ここでは説明のため、次の環境を想定します。(以下の説明では、実際のバージョンや画面とは異なる場合があります。)
- マスター(ID=1)、スレーブ(ID=2)でVCS グループを運用中
- VCSグループのホスト名は「vcg」
- 現在のファームウェアバージョンは5.4.7-2.5
- 新しいファームウェアバージョンは5.4.7-2.6
5.4.7-2.6は説明上使用している架空のファームウェアです。5.4.7-2.5リリース時点では実在しませんのでご注意ください。
[SDカードの準備]
SDカードの読み書きができるPCなどを使って下記の準備をしてください。
- 新しいファームウェアイメージファイルをSDカードのルートディレクトリーにコピーします。
- SDカードオートブート機能で使用する設定ファイル(autoboot.txt)を作成します。本設定ファイルはプレインテキストファイルです。コマンドリファレンスに記載されている書式にしたがって編集してください。
[AlliedWare Plus]
Copy_from_external_media_enabled=yes
Boot_Release=SBx908-5.4.7-2.6.rel
- 前の手順で作成したautoboot.txtをSDカードのルートディレクトリーにコピーします。
[バージョンアップ]
- PC上などで、新しいファームウェアイメージファイルのサイズを確認してください。Windows ならファイルの「プロパティ」や「dir」コマンド、UNIX なら「ls -l」コマンドなどで確認します。
- show file systemsコマンドを実行して、各メンバーのフラッシュメモリー空き容量を確認します。
vcg# show file systems ↓
Stack member 1:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 35.5M flash rw flash: static local Y
- - system rw system: virtual local -
...
Stack member 2:
Size(b) Free(b) Type Flags Prefixes S/D/V Lcl/Ntwk Avail
-------------------------------------------------------------------
63.0M 38.5M flash rw flash: static local Y
- - system rw system: virtual local -
...
この例では、メンバー1 の空き容量が35.5MByte、メンバー2 の空き容量が38.5MByteであると確認できます。空き容量とイメージファイルのサイズを比較して、すべてのメンバーにイメージファイルを格納するのに充分な空きがあることを確認してください。
いずれかのメンバーの空き容量が足りない場合は、deleteコマンドで不要なファイルを削除して空きを作ってください。たとえば、メンバー2 の空き容量が足りない場合は、次のようにして不要なファイルを削除します。
vcg# dir vcg-2/flash:/*.rel ↓
...
1401740 -rw- Jan 01 2011 00:00:00 vcg-2/flash:/SBx908-nolonger-used.rel
...
vcg# delete vcg-2/flash:/SBx908-nolonger-used.rel ↓
Deleting....................................................
Successful operation
ここで、コマンド中の「vcg-2/」はスレーブのファイルシステムを指定するための書式で、VCSグループのホスト名(例ではvcg)、半角ハイフン、スレーブのスタックメンバーID(例では2)、半角スラッシュをつなげたものです。「vcg-2/」は一例ですので、実際にはご使用の環境におけるホスト名とスタックメンバーID を指定してください。たとえば、VCS グループのホスト名が「november」でスレーブのスタックメンバーID が「3」のときは、「vcg-2/」の代わりに「november-3/」と指定します。なお、ホスト名を明示的に設定していない場合、VCS グループのホスト名は「awplus」となります(たとえば、「awplus-2/」などと指定します)。
スレーブファイルシステムの指定方法については、応用編をご覧ください。
- レジリエンシーリンクが接続されていることを確認します。
- VCSのスレーブ側のスタックケーブルを抜きます。
- コンソール上でautoboot enableコマンドを実行し、SDカードオートブート機能を有効にします。同コマンドの設定は、実行と同時にシステムファイルに保存されるため、copyコマンドやwrite fileコマンド、write memoryコマンドなどでコンフィグに保存する必要はありません。
vcg# configure terminal ↓
Enter configuration commands, one per line. End with CNTL/Z.
vcg(config)# autoboot enable ↓
- 現在のコンフィグを念のためバックアップします。ここでは例としてbefore-autoboot-upgrade.cfgというファイル名でバックアップしています。
vcg(config)# exit ↓
vcg# copy running-config before-autoboot-upgrade.cfg ↓
- SDカードをマスターのUSBポートに挿入します。
- 次のコマンドを実行して、マスターを再起動します。マスターの再起動により、スレーブがマスターに昇格します。
vcg# reload ↓
- 旧マスターの再起動中に、SDカードオートブート機能が動作していることを示す次のメッセージが表示され、その後再度旧マスターが自動的に再起動します。
09:28:21 awplus Autoboot: autoboot.txt file detected
awplus login:
09:29:21 awplus Autoboot: Restoring release from card:/SBx908-5.4.7-2.6.rel to flash:SBx908-5.4.7-2.6.rel. This may take several minutes to complete.
09:29:21 awplus Autoboot: Please wait until the device reboots.
09:30:21 awplus Autoboot: Release successfully restored
09:30:21 awplus Autoboot: Autoboot restore successful, rebooting device.
- 旧マスターの2回目の起動が完了して、ログインプロンプトが表示されたら、旧スレーブ(現マスター)の電源を切ります。これにより、旧マスターが再びマスターに昇格します。
- 旧スレーブ側のスタックケーブルを接続し、再度電源を入れます。起動中、マスターと同期をとるためにもう一度自動的に再起動します。
- 旧スレーブの再起動が完了したら、マスター側でshow bootコマンドを実行し、SDカード上のautoboot.txtファイルで指定したファームウェアイメージファイルが通常用ファームウェアとして設定されており、実際にロードされていることを確認してください。また、バージョンアップ前に使用していたファームウェアイメージファイルがバックアップ用ファームウェアとして設定されていることを確認してください。問題がなければ、以上でバージョンアップは完了です。
vcg# show boot ↓
Boot configuration
--------------------------------------------------------------------------------
Current software : SBx908-5.4.7-2.6.rel
Current boot image : flash:/SBx908-5.4.7-2.6.rel
Backup boot image : flash:/SBx908-5.4.7-2.5.rel
Default boot config: flash:/default.cfg
Current boot config: flash:/default.cfg (file exists)
Backup boot config: Not set
Autoboot status : enabled
- バージョンアップが完了したら、autoboot enableコマンドをno形式で実行し、SDカードオートブート機能を無効にしてください。
同コマンドの設定は、実行と同時にシステムファイルに保存されるため、copyコマンドやwrite fileコマンド、write memoryコマンドなどでコンフィグに保存する必要はありません。
vcg# configure terminal ↓
Enter configuration commands, one per line. End with CNTL/Z.
vcg(config)# no autoboot enable ↓
SDカード上のファームウェアを通常用ファームウェアに指定する
ファームウェアバージョン5.4.1-0.1 以降では、SDカードまたはSDHCカード(以後、本セクションでは原則としてSDカードと総称します)に保存したファームウェアイメージファイルを、通常用ファームウェアとして直接使用することができます。スタックメンバーのフラッシュメモリー上にファームウェアを保存する必要がないので、スタックメンバーのフラッシュメモリーの空き容量を気にする必要がありません。また、SDカードに保存したコンフィグファイルを通常用コンフィグとして直接使用することもできます。
SDHCカードを使用する場合は、SDHCカードを装着して起動するマスターのブートローダーバージョンが1.1.6以降である必要があります。ブートローダーバージョンはshow systemコマンドの出力結果の「Bootloader version」の項目で確認できます。
vcg# show system ↓
Stack System Status Wed Mar 02 08:05:08 2011
Stack member 1:
Board ID Bay Board Name Rev Serial number
--------------------------------------------------------------------------------
Base 281 SwitchBlade x908 C-2 C1JB9C02U
Expansion 273 Bay1 XEM-12S D-0 A1HC8207X
PSU 298 PSU1 AT-PWR05-AC B-0 100525-000B1
--------------------------------------------------------------------------------
RAM: Total: 513000 kB Free: 408220 kB
Flash: 63.0MB Used: 59.8MB Available: 3.2MB
--------------------------------------------------------------------------------
Environment Status : Normal
Uptime : 0 days 23:52:27
Bootloader version : 1.1.6
Stack member 2:
Board ID Bay Board Name Rev Serial number
--------------------------------------------------------------------------------
Base 281 SwitchBlade x908 D-2 C1JBA2018
Expansion 273 Bay1 XEM-12S D-0 A1HC8A02Q
PSU 298 PSU1 AT-PWR05-AC B-0 100525-000BY
--------------------------------------------------------------------------------
RAM: Total: 513000 kB Free: 410432 kB
Flash: 63.0MB Used: 56.6MB Available: 6.4MB
--------------------------------------------------------------------------------
Environment Status : Normal
Uptime : 0 days 22:50:33
Bootloader version : 1.1.6
本機能を使用するときは、同一種類かつ同一容量のSDカードがスタックメンバーの台数分必要となります。
本機能を使用してファームウェアをバージョンアップする場合は次の手順にしたがってください。ここでは説明のため、次の環境を想定します(以下の説明では、実際のバージョンや画面とは異なる場合があります)。
- マスター(ID=1)、スレーブ(ID=2)でVCS グループを運用中
- VCSグループのホスト名は「vcg」
- 現在のファームウェアバージョンは5.4.7-2.5
- 新しいファームウェアバージョンは5.4.7-2.6
5.4.7-2.6は説明上使用している架空のファームウェアです。5.4.7-2.5リリース時点では実在しませんのでご注意ください。
- show stackコマンドを実行し、VCS グループが正しく構築されていることを確認してください。
vcg# show stack ↓
Virtual Chassis Stacking summary information
ID Pending ID MAC address Priority Status Role
1 - 0015.7793.23cb 128 Ready Active Master
2 - 0015.77df.f59d 128 Ready Backup Member
Operational Status Normal operation
Stack MAC address 0000.cd37.03db (Virtual MAC)
- 新しいファームウェアイメージファイルをSDカードに保存します。新しいファームウェアイメージファイルを保存するのはマスターで使用するSDカードのみでも問題ありませんが、この場合はスレーブで使用するすべてのSDカードに新しいファームウェアイメージファイルを保存できる空き容量があることを確認してください。
- SDカードをすべてのスタックメンバーのSDカードスロットに挿入します。
- boot systemコマンドのbackupパラメーターを使って、SDカードが挿入されていなかったときに使用するバックアップ用ファームウェアを指定します。バックアップ用ファームウェアが設定されていないと、SDカードに保存されているファームウェアを通常用ファームウェアに設定できません。現在通常用ファームウェアとして指定しているファームウェアをバックアップ用ファームウェアとして指定する場合は、「no boot system」を先に実行してください。
vcg# configure terminal ↓
Enter configuration commands, one per line. End with CNTL/Z.
vcg(config)# no boot system ↓
vcg(config)# boot system backup SBx908-5.4.7-2.5.rel ↓
VCS synchronizing file across the stack, please wait...
File synchronization with stack member-2 successfully completed
[DONE]
- boot systemコマンドを使って、SDカードに保存されている新しいファームウェアを通常用ファームウェアに指定します。
vcg(config)# boot system card:/SBx908-5.4.7-2.6.rel ↓
VCS synchronizing file across the stack, please wait.......
File synchronization with stack member-2 successfully completed
[DONE]
- show bootコマンドを実行して、通常用ファームウェアとバックアップ用ファームウェアの設定を確認します。
vcg# show boot ↓
Boot configuration
--------------------------------------------------------------------------------
Current software : SBx908-5.4.7-2.5.rel
Current boot image : card:/SBx908-5.4.7-2.6.rel
Backup boot image : flash:/SBx908-5.4.7-2.5.rel
Default boot config: flash:/default.cfg
Current boot config: flash:/default.cfg (file exists)
Backup boot config: Not set
Autoboot status : disabled
- reload/rebootコマンドもしくは、reload rolling/reboot rollingコマンドによりVCSグループ全体を再起動します。
reload rolling/reboot rollingコマンドは、メジャーバージョンアップには使用できません。
vcg# reload ↓
Are you sure you want to reboot the whole stack? (y/n): y ↓
- 再起動完了後、show systemコマンドでファームウェアバージョンを確認し、show stackコマンドでVCS グループが正しく構築されていることを確認します。問題がなければ、以上でバージョンアップは完了です。
ナビゲーション
■ VCSの高度な使い方については、第4部 応用編をご覧ください。
(C) 2007 - 2018 アライドテレシスホールディングス株式会社
PN: 613-000751 Rev.AK